Parallel computing. Parallel computing and mathematics education. Areas of application of parallel calculations on graphics accelerators
Send your good work in the knowledge base is simple. Use the form below
Students, graduate students, young scientists who use the knowledge base in their studies and work will be very grateful to you.
Posted on http://www.allbest.ru/
Posted on http://www.allbest.ru/
- Introduction
- 1. Relevance of the topic
- 2. Increasing the number of cores
- 3. NVIDIA CUDA technology
- 4. Difference between CPU and GPU
- Conclusion
- Introduction
- Parallelization of calculations is the division of large tasks into smaller ones that can be performed simultaneously. Parallel computing typically requires some coordinated effort. Parallel computing comes in several forms (instruction, bit, data, task levels). Parallel computing has been used for many years mainly in high-performance computing. But the situation in Lately has changed. There was a demand for such calculations due to physical limitations on the growth of processor clock speed. Parallel computing has become a dominant idea in computer architecture. It took the form of multi-core processors.
- The use of parallel computing systems is determined by strategic directions of development in the computer industry. The main circumstance was not only the limitation of the speed of machines based on sequential logic, but also the presence of tasks for which the availability of computer technology is not yet sufficient. Tasks in this category include modeling of dynamic processes.
- The advent of multi-core processors marked a leap in the development of efficient supercomputing, which boasts higher performance/cost ratios than supercomputer-based systems. The use of multi-core processors provides flexibility, in particular, for varying configurations, as well as scaling power in computing systems - from PCs, servers, workstations and ending with cluster systems.
- 1. Relevance of the topic
- In recent years there has been a large number of cheap cluster parallel computing systems, which led to the rapid development of parallel computing technologies, including in the field of high-performance computing. Most major microprocessor manufacturers began to switch to multi-core architectures, which influenced the change in the situation in the field of parallel computing technologies. A change in the hardware base entails a change in the construction of parallel algorithms. For implementation in multi-core computing architectures, new parallel algorithms are needed that take into account new technologies. The efficiency of using computing resources will depend on the quality of the actual parallel applications and specialized libraries aimed at multi-core architectures.
- The use of high-performance technology in modeling real technical, economic, and other processes described by systems of high-dimensional ordinary differential equations is not only justified, but also necessary. Parallelization of calculations in multiprocessor and parallel structures is effective ways increase productivity. So, the use of parallel computing systems is quite an important direction in the development of computer technology.
2. Increasing the number of cores
The first processor for mass use was the POWER4 with two PowerPC cores on a single chip. Released by IBM in 2001.
Processor manufacturers Intel, AMD, IBM, ARM have recognized increasing the number of cores as one of the priority areas for increasing performance.
In 2011, 8-core processors for home PCs and 16-core processors for server systems were released.
There are developments of processors with large quantity m cores (more than 20), which have found application in specific devices.
Dual-core processors existed earlier, for example IBM PowerPC-970MP (G5H). But such processors were used in a narrow range of specialized tasks.
In April 2005, AMD introduced the 2-core Opteron processor. AMD64 architecture. designed for servers. In May 2005, Intel introduced the Pentium D processor. x86-64 architecture. Became the first 2 nuclear processor for home PCs.
In March 2010, AMD introduced 12-core serial server processors Opteron 6100 (x86/x86-64 architecture).
In August 2011, AMD introduced the 16-core Opteron 6200 series server processors. The Interlagos processor contains two 8-core (4-module) chips in a single package and is compatible with the AMD Opteron 6100 series platform (Socket G34).
3. NVIDIA CUDA technology
A large amount of parallel computing is associated with 3D games. Parallel vector computing on general-purpose devices with multi-core processors is used in 3D graphics, achieving high peak performance. Universal processors cannot do this. The maximum speed is achieved only in a number of convenient tasks, having some limitations. But still, such devices are widely used in areas where they were not originally intended. For example, the Cell processor, developed by the Sony-Toshiba-IBM alliance in the Sony PlayStation 3 game console, or modern video cards from NVIDIA and AMD.
A few years ago, general purpose non-graphical computing technologies GPGPU for 3D video accelerators began to appear. Modern video chips have hundreds of mathematical execution units, such power can help significantly speed up many computationally intensive applications. The current generations of GPUs have a flexible architecture, which, together with software and hardware architectures and high-level languages, makes it possible to make them much more accessible.
The emergence of fairly fast and flexible shader programs has interested developers in creating GPGPUs that are capable of executing modern video chips. Developers wanted to use the GPU to calculate not only images in gaming and 3D applications, but also to use them in other areas of parallel computing. To do this, we used the API of OpenGL and Direct3D graphics libraries. Data was transferred to the video chip as textures, and computational programs were placed in the form of shaders. The main disadvantage of this method is the significant complexity of programming, low data exchange between the GPU and CPU, and some other limitations.
Leading video chip manufacturers NVIDIA and AMD presented platforms for parallel computing - CUDA and CTM, respectively. Video cards now have hardware support for direct access to computing resources. CUDA is an extension of the C programming language. CTM is more similar to virtual machine, which only executes assembly code. Both platforms have removed restrictions previous versions GPGPU, which used the traditional graphics pipeline, and of course the Direct3D and Open GL graphics libraries.
OpenGL is more portable and also versatile due to its open source nature. But it will not allow the same code to be used on chips from different manufacturers. Such methods have many disadvantages, they are not convenient, and have little flexibility. They also do not allow you to use the specific capabilities of some video cards, for example, fast shared memory.
This is exactly what happened to NVIDIA to release the CUDA platform - a C-like programming language, equipped with its own compiler, and also has libraries for GPU computing. Writing good code for video chips is not easy, but CUDA gives you more control over the video card hardware. CUDA appeared with video cards of the 8 series. CUDA version 2.0 appeared, which supports double-precision calculations in 32- and 64-bit Windows, Linux, MacOS X.
4. Difference between CPU and GPU
The increase in clock speed ended due to high power consumption. The increase in performance occurs due to an increase in the number of cores on one chip. On this moment For home users, processors with up to eight cores and a number of threads of up to 16 are sold. In such processors, each core operates separately.
Special vector capabilities (SSE instructions) for 4-component (single-precision floating-point) and 2-component (double-precision) vectors appeared in general-purpose processors due to the high demands of graphics applications. Therefore, the use of GPU is more profitable, because They were originally designed for such tasks.
In NVIDIA chips, the main unit is a multiprocessor with 8-10 cores and about a hundred ALUs with several thousand registers and large shared memory. The video card has global memory accessible from all multiprocessors, local memory in each multiprocessor, and also has memory for constants.
In GPUs, the cores are SIMD (single instruction stream, multiple data stream) cores. These cores execute the same instructions at the same time. This is the style of programming graphical algorithms. It is specific, but allows you to increase the number of computational units due to its simplicity.
The main differences between the architectures (GPU and CPU): CPU cores execute one thread of sequential instructions with maximum performance, GPU executes a large number of parallel instruction threads. General-purpose processors are aimed at achieving high performance of a single instruction thread, processing numbers with and without floating point. Memory access is random.
The policy of CPU developers is to get more instructions executed in parallel to increase performance. Therefore, starting with Intel Pentium processors, superscalar execution technology appeared, which represents the execution of 2 instructions per clock cycle, and the Pentium Pro processor was distinguished by out-of-order execution of instructions.
Video chips have a simpler operation and are parallelized from the start. The chip takes a group of polygons, all the necessary operations, and produces pixels. Polygons and pixels are processed independently of each other. That's why the GPU has such a large number of processors. Also, modern GPUs are capable of executing more than one instruction per clock cycle.
Another difference between a CPU and a GPU: the principle of memory access. In GPU it is coherent and predictable, because if textures were counted, it means that after some time the turn of neighboring textures will come. Therefore, the memory organization of the video card and the central processor are different. And for this reason the video chip does not need cache memory big size, and textures only require about 128-256 kB.
Working with memory is also different. CPUs have built-in memory controllers, GPUs usually have several of them, up to eight 64-bit channels. In addition, very fast memory is used, therefore, the memory bandwidth is higher, which is a plus for parallel calculations operating with huge data streams.
In a CPU, a large number of transistors are spent on command buffers, hardware branch prediction, and huge amounts of cache memory. All these blocks are needed to speed up the few command streams. In GPUs, transistors go to arrays of execution units, small shared memory, flow control units, and memory controllers. All this does not speed up the execution of individual threads, but allows you to process a huge number of them at the same time.
Caching. The CPU uses the cache to reduce memory access latency, resulting in increased performance. The GPU uses cache to increase throughput. The CPU reduces memory access latency through a large cache and code branch prediction. These hardware pieces are large on the chip, hence they consume a lot of power. GPUs solve the problem of memory access latency in another way: executing thousands of threads simultaneously. When one thread is waiting for data, another thread performs the calculations without waiting or delaying.
In general, we can draw the following conclusion: video chips are designed for parallel calculations with a large amount of data and a large number of arithmetic operations.
5. First use of calculations on graphics accelerators
The history of using chips for mathematical calculations began a long time ago. The very first attempts were primitive and used some functions from Z-buffering and rasterization. But with the advent of shaders, acceleration began. In 2003 SIGGRAPH has a new section for computing, and it received GPGPU.
BrookGPU. Well-known compiler of the Brook programming language. Is streaming. It was specifically designed for GPU computing. The developers used API: Direct3D or OpenGL. This significantly limited the use of GPUs, because shaders and textures were used in 3D graphics, and parallel programming specialists are not required to know anything. They use current threads and cores. Brook was able to help a little with this task. Extensions to the C language helped hide the 3D API from programmers and provide the video chip as a parallel coprocessor. The compiler compiled the code and linked it to the DirectX, OpenGL or x86 library.
6. Areas of application of parallel calculations on graphics accelerators
Here are the average figures for the increase in computing performance obtained by researchers around the world. When switching to a GPU, the performance increase is on average 5-30 times, and in some examples it reaches up to 100 times (usually this is code that is unsuitable for calculations using SEE.
Here are some examples of accelerations:
· Fluorescence microscopy - 12 times;
· Molecular dynamics - 8-16 times;
· Electrostatics (direct and multi-level Coulomb summation) - 40-120 times and 7 times.
core processor graphics
Conclusion
In the abstract, we were able to consider parallel computing on multi-core processors, as well as CUDA and CTM technologies. The difference between CPU and GPU was discussed, what were the difficulties of using video cards in parallel computing without CUDA technology, and areas of application were considered.
The abstract did not consider the use of parallel computing in central processors with an integrated video core. These are AMD A-series processors (AMD A10, AMD A8, AMD A6, AMD A4) and Intel i3/i5/i7 series processors with built-in HD Graphics video core.
List of used literature
1. Website ixbt.com, owner of Byrds Research and Publishing, Ltd
2. Website wikipedia.org, owner Wikimedia Foundation
3. Website nvidia.ru, owner of NVIDIA corporation
Posted on Allbest.ru
...Similar documents
The batch method as the main method of performing communication operations, its content and requirements. Estimation of the complexity of a data transfer operation between two cluster nodes. Stages of development of parallel algorithms (parallelization).
presentation, added 02/10/2014
Introduction to the history of the development of multiprocessor systems and parallel computing. Personal computers as common single-processor systems on Intel platform or AMD running single-user operating systems.
presentation, added 02/22/2016
Classification of parallel computing systems. Essential concepts and components of parallel computers, their components. Features of the classifications of Hender, Hockney, Flynn, Shore. Systems with shared and local memory. Methods for dividing memory.
course work, added 07/18/2012
Mathematical basis of parallel computing. Properties of Parallel Computing Toolbox. Development of parallel applications in Matlab. Examples of programming parallel tasks. Calculation of a definite integral. Serial and parallel multiplication.
course work, added 12/15/2010
Development of OS concepts and capabilities. Parallel computer systems and features of their OS. Symmetric and asymmetric multiprocessor systems. Types of servers in client-server systems. OS for cloud computing. Cluster computing systems.
lecture, added 01/24/2014
Technology for developing parallel programs for multiprocessor computing systems with shared memory. Syntax, semantics and structure of the OpenMP model: directives, procedures and environment variables. Parallelization of data and operations, synchronization.
presentation, added 02/10/2014
Parallel computing systems, their general characteristics and functional features, assessment of capabilities, internal structure and interconnection of elements, types: single- and multiprocessor. Parallel form of the algorithm, its representation and implementation.
test, added 06/02/2014
Advantages of multiprocessor systems. Creating a program that implements the operation of a multiprocessor system with shared processing memory various quantities applications, as well as different numbers of processors. Models of calculations on vector and matrix computers.
course work, added 06/21/2013
Abstract models and methods of parallel data processing, permissible error of calculations. The concept of a parallel process, their synchronization and parallelization granules, the definition of Amdahl's law. Architecture of multiprocessor computing systems.
thesis, added 09.09.2010
Single-processor computing systems cannot cope with solving military applied problems in real time, therefore, to increase the performance of military computing systems, multiprocessor computing systems (MCS) are used.
Ministry of Education and Science of the Russian Federation
Federal Agency for Education
South Russian State Technical University
(Novocherkassk Polytechnic Institute)
Shakhty Institute (branch) SRSTU (NPI)
LECTURES ON DISCIPLINE
"PARALLEL COMPUTING"
Mines - 2010
Introduction
Basic Concepts
1. General issues of solving “big problems”
1.1 Modern problems of science and technology that require supercomputers to solve
1.2.2 Abstract parallel computing models
1.2.3 Methods of parallel data processing, calculation error
1.3 The concept of a parallel process and parallelization granules
1.4 Interaction of parallel processes, process synchronization
1.5 Possible acceleration in parallel computing (Amdahl's law)
2. Principles of constructing multiprocessor computing systems
2.1 Architecture of multiprocessor computing systems
2.2 Distribution of calculations and data in multiprocessor computing systems with distributed memory
2.3 Classification of parallel computing systems
2.4 Multiprocessor computing systems with distributed memory
2.4.1 Massively parallel supercomputers of the Cry T3 series
2.4.2 BEOWULF class cluster systems
Conclusion
Bibliography
Introduction
Even at the dawn of the computer era, around the middle of the last century, designers of electronic computers thought about the possibility of using parallel computing in computers. After all, increasing speed only by improving the electronic components of a computer is a rather expensive method, which, moreover, faces limitations imposed by physical laws. Thus, parallel data processing and command parallelism were introduced into the design of computers, and now any “personal computer” user, perhaps without knowing it, works on a parallel computer.
One of the noticeable trends in the development of mankind is the desire to model the processes of the surrounding reality as strictly as possible in order to both improve living conditions in the present and predict the future as accurately as possible. Mathematical methods and digital modeling techniques in many cases make it possible to solve such problems, but over time there is a serious qualitative and quantitative complication of the technology for solving problems. In many cases, the limitation is the lack of computing power of modern electronic computers, but the importance of the problems being solved has attracted huge financial resources to the field of creating highly complex electronic computers.
For some time now, increasing the speed of computers of traditional (called “von Neumann”) architecture has become prohibitively expensive due to technological limitations in the production of processors, so developers have turned their attention to another way to increase productivity - combining electronic computers into multiprocessor computing systems. In this case, individual program fragments are executed in parallel (and simultaneously) on different processors, exchanging information via an internal computer network.
The idea of combining electronic computers in order to increase both productivity and reliability has been known since the late fifties.
The requirements to obtain maximum performance at minimum cost led to the development of multiprocessor computing systems; systems of this kind are known that combine the computing power of thousands of individual processors. The next stage is attempts to unite millions of heterogeneous computers on the planet into a single computing complex with enormous performance via the Internet. Today, the use of parallel computing systems is a strategic direction in the development of computer technology. Development of "iron" are necessarily supported by the improvement of algorithmic and software components - parallel programming technologies.
The method of parallelizing calculations has existed for a long time; organizing the joint functioning of many independent processors requires serious theoretical and practical research, without which a complex and relatively expensive multiprocessor installation often not only does not exceed, but is inferior in performance to a traditional computer.
The potential for parallelization is not the same for computing tasks various types– it is significant for scientific programs containing many cycles and lengthy calculations and significantly less for engineering problems, which are characterized by calculations using empirical formulas.
Let's consider two main questions:
1. Multiprocessor computing systems - (massively parallel supercomputers) Cray T3D(E) with a number of processors from 40 to 2176. These are supercomputers with distributed memory on RISC processors of the Alpha21164A type, with a communication network topology - a three-dimensional torus, a UNIX operating system with a microkernel and translators for FORTRAN, HPF, C/C++ languages. Supported programming models: MPI, PVM, HPF.
2. Beowulf clusters of workstations. Workstation clusters are a collection of workstations connected to a local network. A cluster is a computing system with distributed memory and distributed control. A cluster system can have performance comparable to that of supercomputers. Workstation clusters are usually called Beowulf clusters (Beowulf cluster - after the project of the same name), connected local network Ethernet and use the Linux operating system.
Basic Concepts
The most common programming technology for cluster systems and parallel computers with distributed memory is currently MPI technology. The main way parallel processes interact in such systems is by passing messages to each other. This is reflected in the name of this technology - Message Passing Interface. The MPI standard defines an interface that must be followed both by the programming system on each computing platform and by the user when creating their programs. MPI supports Fortran and C languages. Full version interface contains descriptions of more than 125 procedures and functions.
The MPI interface supports the creation of parallel programs in the MIMD (Multiple Instruction Multiple Data) style, which involves combining processes with different source codes. However, writing and debugging such programs is very difficult, so in practice programmers much more often use the SPMD (Single Program Multiple Data) model of parallel programming, within which the same code is used for all parallel processes. Nowadays, more and more MPI implementations support working with so-called "threads".
Since MPI is a library, when compiling a program it is necessary to link the corresponding library modules.
After receiving the executable file, you need to run it on the required number of processors. After launch, the same program will be executed by all running processes, the execution result, depending on the system, will be output to the terminal or written to a file.
An MPI program is a set of parallel interacting processes. All processes are spawned once, forming a parallel part of the program. During the execution of an MPI program, the creation of additional processes or the destruction of existing ones is not allowed (in further versions of MPI this possibility appeared). Each process operates in its own address space; there are no shared variables or data in MPI. The main way of interaction between processes is by sending messages explicitly.
To localize the interaction of parallel program processes, you can create groups of processes, providing them with a separate environment for communication - a communicator. The composition of the groups formed is arbitrary. Groups can completely coincide, be part of one another, not intersect, or partially intersect. Processes can only interact within a certain communicator; messages sent in different communicators do not intersect or interfere with each other. Communicators have the integer type in the Fortran language (in the C language, the predefined MPI Comm type).
When a program starts, it is always assumed that all spawned processes operate within the framework of a comprehensive communicator. This communicator always exists and serves for interaction between all running processes of the MPI program. All interactions between processes take place within a specific communicator; messages transmitted in different communicators do not interfere with each other.
Reduced Instruction Set Processors (RISC). The RISC (Reduced Instruction Set Computer) architecture of the processor is based on the idea of increasing the speed of its operation by simplifying the instruction set.
Research has shown that 33% of the instructions in a typical program are data transfers, 20% are conditional branches, and another 16% are arithmetic and logical operations. In the vast majority of instructions, address calculation can be performed quickly, in one cycle. More complex addressing modes are used in approximately 18% of cases. About 75% of the operands are scalar, that is, variables of integer, real, character, etc., and the rest are arrays and structures. 80% of scalar variables are local, and 90% of structural variables are global. Thus, most operands are local operands of scalar types. They can be stored in registers.
According to statistics, most of the time is spent on processing "subroutine call" statements. and ";return from subroutine";. When compiled, these statements produce long sequences of machine instructions with a large number of memory accesses, so even if the share of these statements is only 15%, they consume the bulk of the processor time. Only about 1% of routines have more than six parameters, and about 7% of routines contain more than six local variables.
From examining these statistics, it was concluded that the typical program is dominated by simple operations: arithmetic, logical and data transfers. Simple addressing modes also dominate. Most operands are scalar local variables. One of the most important resources for increasing productivity is optimizing these operators.
The RISC architecture is based on the following principles and ideas. The set of instructions should be limited and include only simple instructions, the execution time of which after sampling and decoding is one clock cycle or a little more. Pipeline processing is used. Simple RISC instructions can be implemented efficiently in hardware, while complex instructions can only be implemented in microprogramming. The design of the control device in the case of RISC architecture is simplified, and this allows the processor to operate at large clock speeds. Using simple commands allows you to effectively implement both pipeline data processing and command execution.
Complex instructions take longer to execute on a RISC processor, but their number is relatively small. In RISC processors, a small number of instructions are addressed to memory. Sampling data from random access memory requires more than one clock cycle. Most instructions work with operands located in registers. All commands have a unified format and a fixed length. This makes loading and decoding instructions easier and faster since, for example, the opcode and address field are always in the same position. Variables and intermediate results of calculations can be stored in registers. Taking into account the statistics of the use of variables, most of the local variables and procedure parameters can be placed in registers. When a new procedure is called, the contents of the registers are usually moved into RAM, however, if the number of registers is large enough, it is possible to avoid much of the time-consuming memory exchange operations by replacing them with register operations. Thanks to the simplified architecture of the RISC processor, there is space on the chip to accommodate an additional set of registers.
Currently, computing systems with RISC architecture occupy leading positions in the global computer market for workstations and servers. The development of RISC architecture is associated with the development of compilers, which must effectively take advantage of the large register file, pipelining, etc.
1. General issues of solving “big problems”
Under the term ";big problems" They usually understand problems whose solution requires not only the construction of complex mathematical models, but also the carrying out of a huge number of calculations, many orders of magnitude greater than those typical for programmable electronic computers. Here, electronic computers are used with appropriate resources - the size of the operational and external memory, speed of information transmission lines, etc.
The upper limit on the number of calculations for ";large problems"; determined only by the performance of currently existing computing systems. When ";running"; For computational problems in real conditions, the question is not “to solve the problem at all,” but “to solve it in an acceptable time.” (hours/tens of hours).
1.1. Modern tasks of science and technology that require
for solving supercomputers
Quite often one has to deal with problems that, while representing considerable value for society, cannot be solved with the help of relatively slow computers office or home class. The only hope in this case rests on high-speed computers, which are commonly called supercomputers. Only machines of this class can cope with processing large amounts of information. This could be, for example, statistical data or the results of meteorological observations, financial information. Sometimes processing speed is critical. Examples include weather forecasting and climate change modeling. The earlier a natural disaster is predicted, the greater the opportunity to prepare for it. An important task is the modeling of medicines, deciphering the human genome, tomography, including medical, and exploration of oil and gas fields. There are many examples that can be given.
Modeling the processes of the surrounding reality in order to both improve living conditions in the present and reliably predict the future is one of the trends in the development of mankind. Mathematical methods and digital modeling techniques in many cases make it possible to solve such problems, however, over time, the technology for solving such problems becomes more complex. In many cases, the limitation is the lack of computing power of modern electronic computers.
The requirements to obtain maximum performance at minimum cost led to the development of multiprocessor computing systems; systems of this kind are known that combine the computing power of thousands of individual processors.
Listed below are some areas of human activity that require supercomputer power using parallel computing for their solution:
Predictions of weather, climate and global atmospheric changes
Materials Science
Construction of semiconductor devices
Superconductivity
Pharmaceutical development
Human genetics
Astronomy
Transport problems of large dimension
Hydro and gas dynamics
Controlled thermonuclear fusion
Oil and gas exploration
Computational problems in ocean sciences
Speech recognition and synthesis, image recognition
One of the biggest challenges is climate system modeling and weather prediction. In this case, the equations of continuum dynamics and the equations of equilibrium thermodynamics are solved jointly numerically. To simulate the development of atmospheric processes over 100 years and a number of discretization elements of 2.6×106 (a grid with a step of 10 in latitude and longitude over the entire surface of the Planet with 20 layers in height, the state of each element is described by 10 components) at any moment in time the state of the earth atmosphere is described by 2.6×107 numbers. With a time sampling step of 10 minutes, 5 × 104 ensembles need to be determined over the simulated time period (that is, 1014 required numerical values of intermediate calculations). When estimating the number of computational operations required to obtain each intermediate result at 102÷103 total number floating-point calculations required to conduct a numerical experiment with a global atmospheric model reach 1016÷1017.
A supercomputer with a performance of 1012 op/sec in the ideal case (full load and efficient algorithmization) will perform such an experiment within several hours; To carry out the complete modeling process, it is necessary to run the program multiple times (tens/hundreds of times).
The problem of supercomputing is so important that many states supervise work in the field of supercomputer technologies.
State support is directly related to the fact that independence in the production and use of computer technology is in the interests of national security, and the country’s scientific potential is directly related and is largely determined by the level of development of computer technology and software.
For the purpose of objectivity in comparison, the performance of super-electronic computers is calculated based on the execution of a previously known test task (“benchmark”, from the English benchmark). Peak performance is determined by the maximum number of operations that can be performed in a unit of time in the absence of connections between functional devices, characterizes the potential capabilities of the equipment and does not depend on the program being executed.
The disadvantage of the method of assessing peak performance as the number of instructions executed by a computer per unit of time (MIPS, Million Instruction Per Second) gives only the most general idea of performance, since it does not take into account the specifics of specific programs (it is difficult to predict at what number and which specific processor instructions the user's program).
It should be noted that there are arguments against the widespread practical use of parallel computing:
Parallel computing systems are prohibitively expensive. According to Grosch's law, confirmed by practice, computer performance grows in proportion to the square of its cost; As a result, it is much more profitable to obtain the required computing power by purchasing one powerful processor than using several slower processors.
Counter argument. The increase in speed of sequential electronic computers cannot continue indefinitely; computers are subject to rapid obsolescence and frequent financial costs are required for the purchase of new models. The practice of creating parallel computing systems of the Beowulf class has clearly shown the cost-effectiveness of this particular path.
When organizing parallelism, performance losses grow too quickly. According to Marvin Minsky's hypothesis, the computational acceleration achieved when using a parallel system is proportional to the binary logarithm of the number of processors (with 1000 processors, the possible acceleration is only 10).
Counter argument. The given speedup estimate is correct for parallelizing certain algorithms. However, there are a large number of problems, when solved in parallel, close to 100% utilization of all available processors of a parallel computing system is achieved.
Serial computers are constantly improving. According to the well-known Moore's law, the complexity of sequential microprocessors doubles every 18 months, so the required performance can be achieved on “conventional” microprocessors. serial computers.
Counter argument. A similar development is characteristic of parallel systems.
However, the use of parallelism allows you to obtain the necessary acceleration of calculations without waiting for the development of new, faster processors. The efficiency of parallelism strongly depends on the characteristic properties of parallel systems. All modern serial electronic computers operate in accordance with the classical von Neumann circuit; parallel systems are distinguished by a significant variety of architecture and the maximum effect from the use of parallelism can be obtained when full use all the features of the equipment (the consequence is the transfer of parallel algorithms and programs between different types systems is difficult and sometimes impossible).
Counter argument. Given the actual variety of architectures of parallel systems, there are also certain “established” ones. ways to ensure parallelism. Invariance of the created software is achieved through the use of standard software support for parallel computing (software libraries PVM, MPI, DVM, etc.). PVM and MPI are used in Cray-T3 supercomputers.
Over decades of operation of serial electronic computers, a huge amount of software has been accumulated that is focused on serial electronic computers; processing it for parallel computers is practically impossible.
Counter argument. If these programs provide a solution to the assigned tasks, then their processing is not necessary at all. However, if sequential programs do not allow obtaining solutions to problems in an acceptable time, or there is a need to solve new problems, then the development of new software is necessary and it can initially be implemented in parallel execution.
There is a limitation on the speedup of calculations with parallel implementation of the algorithm compared to sequential implementation.
Counter argument. In fact, there are no algorithms at all without a (certain) share of sequential calculations. However, this is the essence of a property of the algorithm and has nothing to do with the possibility of parallel solution of the problem in general. It is necessary to learn how to apply new algorithms that are more suitable for solving problems on parallel systems.
Thus, for every critical consideration against the use of parallel computing technologies, there is a more or less significant counterargument.
1.2 Parallel data processing
1.2.1 Fundamental possibility of parallel processing
Almost all algorithms developed to date are sequential. For example, when evaluating the expression a + b × c, you must first perform the multiplication and only then perform the addition. If electronic computers contain addition and multiplication nodes that can operate simultaneously, then in this case the addition node will be idle waiting for the multiplication node to complete its work. It is possible to prove the statement that it is possible to build a machine that will process a given algorithm in parallel.
It is possible to build m processors that, when operated simultaneously, produce the desired result in one single clock cycle of the computer.
Such "multiprocessor" machines can theoretically be built for each specific algorithm and, it would seem, “bypass” sequential nature of the algorithms. However, not everything is so simple - there are infinitely many specific algorithms, so the abstract reasoning developed above is not so directly related to practical significance. Their development convinced us of the very possibility of parallelization, formed the basis of the concept of unlimited parallelism, and made it possible to consider from a general perspective the implementation of so-called computing environments - multiprocessor systems dynamically configured for a specific algorithm.
Plaksin M.A.
National Research University Higher School of Economics (Perm branch), Perm, Ph.D., Associate Professor of the Department of Information Technologies in Business, mapl @ list. ru
"SUPERCOMPUTERS" VS "PARALLEL PROGRAMMING". “PARALLEL PROGRAMMING” VS “COLLABORATIVE ACTIVITY”. HOW TO STUDY THE TOPIC “PARALLEL COMPUTING” IN SECONDARY SCHOOL?
KEYWORDS
Computer science, parallel programming, parallel computing, parallel algorithms, supercomputers, primary school, secondary school, TRIZformashka.
ANNOTATION
The article is devoted to the issue of including the topic “parallel computing” in the school computer science course. A number of problems arising in this case are mentioned, the purpose of studying the topic, the selection of material, some proposals for teaching methods, mechanisms for testing the proposed methodology and the accumulated experience are considered. The question of the place of this material in the curriculum is not addressed.
The current stage of development of computer science is associated with the massive spread of parallelism of calculations at all levels (multi-machine clusters, multiprocessor computers, multi-core processors).
The massive spread of parallelism has serious consequences that have yet to be identified and analyzed. Let's start by listing some theoretical problems.
The modern theory of algorithms was created with the concept of a sequential algorithm in mind. How will the refusal to require a sequence of steps affect the concept of an algorithm?
For at least the last 20 years, the concept of “algorithm” has been introduced in schools inextricably linked with the concept of “performer”. This is natural for a sequential algorithm. What to do with a parallel algorithm? Is it performed by one performer or a group of performers? To be specific, let’s take the computer training program “Tank Crew” as an example. In this program, the student is required to program the actions of a tank crew consisting of three people: a gunner, a driver and a loader. Each of them has its own command system. In order to complete a combat mission (hit all targets), all crew members must act in concert. For an example of the playing field for the Tank Crew program, see Fig. 1.
Question: should these three actors be considered as independent performers or as three components (devices) of one complex performer? For the tank crew, the second option seems more natural, since not a single character is able to complete the task on his own. But what if the game becomes more complicated, and a combat mission is assigned to two tanks at once? For three tanks? Three members of one crew can well be considered as three parts of one performer. But each crew is obviously an independent performer. This means that a parallel algorithm for several tanks will be executed by a group of executors at once. It turns out that for a parallel algorithm it is necessary to consider both possibilities: the execution of parallel actions by one executor and by a group of executors. In the case of a tank crew, drawing the line is easy. The performer is the one who is able to solve the task. This executor may consist of several components, each of which performs a certain part of the task, but cannot independently complete the entire task without the help of other components. But whether the separation of “whole performers” and parts of a complex performer will always be as simple is impossible to say now.
File 1*ra Window About the program
Vpolyet everything
Bbno.n«fTb to the highlighted line
Return to initial page**"
would popnlt step by step (after executing the “.order command nesykoa^“ the button gV ygolg “n-b next uwr” will be pressed)
Ё ГГВД iTHWTt. special step
Information step by step
Fig.1. Fragment of the playing field of the Tank Crew program
Identification of the parts of the performer that are capable of independent actions requires that these parts be named somehow. Moreover, the name must allow recursion, since the acting parts of the performer themselves may have a complex structure.
It is necessary to agree on a term to designate a group of cooperative performers. The term “command” is not suitable; it is associated with the “executor command system” and with “central processor commands”. "Collective of performers"? "Brigade of performers"?
Sh. Algorithm
n Hitting1"; Driver Charger
1 Measure orun* on “master sgkll V Stop V Charge 1
g Pci V Stop V Charge 2
3 Wholesale! V Turn clockwise 90 degrees V Charge 1 V
L V V first V Charge? V
5 Fire! V Stop V Charge 1
Í P^chm V St*p V Zaryasya? V
7 Fire! V Stop V Charge 1 V
3 Pa^ V Turn clockwise 45 degrees V Charge 2 V
S Pause V Start V Pause V
10 Pvdea V Forward V Pause ¿d
11 Plrl V Forward V Pause V
12 Paum V Turn clockwise 45 degrees V Pause V
13 Padm V Forward V Pause V
14 V
Fig.2. Fragment of the program for the “Tank Crew” (example of command lines) The traditional concept of the “executor command system” (SCS) and the concept of the team itself require improvement. If we believe that three members of a tank crew form a single performer, then what should be considered the SKI of this performer? And what is considered a team? Or leave the concept of SKI for each character? That is, this is no longer a system of commands of the EXECUTOR, but a system of commands of one of the components of the performer (for which there is no name yet)?
It is convenient to expand the concept of a team to a “line of commands.” For an example of tank crew command lines, see Fig. 2. However, the concept of a “line of commands” only works well for linear algorithms. In other cases, the rulers are formed dynamically. It is impossible to depict them in the form of a visual table.
Among the properties of algorithms, a new practically significant characteristic: ability to parallelize. A clarifying question is about the possible degree of parallelization (to what extent does it make sense to increase the number of processors when executing a given algorithm).
A separate issue is methods for parallelizing existing sequential algorithms.
Until recently, parallel programming was the province of a small number of highly qualified system programmers. Today it is becoming part of professional competence. But parallel programming technology differs significantly from traditional sequential programming. In support of this statement, following L.L. Bosova, we will quote the largest Russian specialist in the field of parallel computing V.V. Vojvodina:
“... The mastery of parallel architecture computing technology... by young specialists comes with great difficulties. In our opinion, this is due to the fact that acquaintance with parallel computing, as well as education in this area in general, does not begin with where one should begin. In addition, what you need to start with is not covered in any courses at all. Opportunity quick solution tasks for computer technology Parallel architecture forces users to change the entire habitual style of interaction with computers. Compared to, for example, personal computers and workstations, almost everything changes: other programming languages are used, most algorithms are modified, users are required to provide numerous non-standard and difficult-to-obtain characteristics of the tasks being solved, the interface ceases to be friendly, etc. An important fact is that failure to fully take into account new operating conditions can significantly reduce the efficiency of using new and, moreover, quite expensive equipment.”
“It is only important that the student learns as early as possible that there are other ways of organizing computational processes, and not just the sequential execution of “operation by operation,” that the most powerful modern computer technology is built on these other methods, that only with such technology it is possible to solve large problems. industrial and scientific tasks, etc. It is important, first of all, to draw students’ attention as early as possible to the need for a critical attitude towards the philosophy of sequential computing. After all, it is this philosophy that they have to deal with throughout their entire education, both at school and at university. And it is precisely this philosophy that hinders the understanding of the features of working on parallel architecture computers.”
Today we need methods for mass training in parallel programming technology. The author of this article believes that in the learning process the time has come for a revolution in the relationship between sequential and parallel programming. Until now, we first taught sequential programming, and then - parallelization of sequential algorithms. Now we need to raise the question of teaching parallel programming right away. A sequential algorithm should be considered as a certain part of a parallel algorithm, which does not require communication with its other parts. How to do this is an open question. There are still some ideas that need practical implementation and testing. It is hoped that in a year at the next conference it will be possible to discuss the results obtained.
Thirty years ago, the beginning of mass computerization of production required an increase in the level of computer literacy of the population. This led to the introduction of computer science into the school curriculum in 1985. But the computer science course in the Soviet (then Russian) version was not limited to “push-button computer science” - to mastering the technology of working with packages application programs and computer games. He began to change the thinking style of the younger generation. First of all, this concerned algorithmicity, accuracy, and rigor. Then the computer science course incorporated elements of logic and systems analysis. Subsequently, all this greatly simplified the distribution of much-needed technology in the 21st century. project approach. The talk now is that over the next decade, parallel algorithms should become
element of the general culture of thinking. Question: how will mastering the concept of a parallel algorithm affect the thinking of the next generation, what will the restructuring of consciousness “in a parallel way” lead to?
The massive spread of parallel information processing makes it urgent to move the relevant concepts into the category of publicly accessible and general cultural ones. Familiarity with parallel algorithms should become part of literacy, just as basic concepts of algorithm theory have become over the past quarter century. This can be done only in one way - by including relevant topics in the school computer science course. This means that we need a methodology for initial acquaintance with parallel programming at the high school level.
Historically, the first attempt to include the topic of parallel computing in a school computer science course was made twenty years ago. Twenty years ago, in a course called “Algorithmics”, a “Construction Director” was described, who commanded the parallel actions of several teams building a structure from rectangular and triangular blocks. Moreover, a software implementation was created for this performer. Alas! This wonderful methodological development was not in demand in the mid-90s. She was almost twenty years ahead of her time!
Today, the situation is such that the topic of parallel computing in high school is primarily related to the topic of supercomputers. It is on supercomputers that the authors of various methodological developments focus the attention of students, even when this is not necessary. Suffice it to say that the corresponding section in the journal “Informatics at School” is called “Supercomputer Education at School.” This situation has both positive and negative sides. Among the positive aspects are:
The topic of supercomputers is of interest in society, including among students. This interest is repeated on modern level the interest that half a century ago aroused in large machines - the supercomputers of their time;
Organizational support from the supercomputing community. Every summer, the Faculty of Computational Mathematics and Cybernetics of Moscow State University hosts the Summer Supercomputer Academy. And every summer, within the framework of this Academy, a school track for computer science teachers is organized. Training is provided free of charge. Nonresident students are provided with housing on very favorable terms. At the Russian Supercomputing Days conference in September 2015, a school section and master class for computer science teachers were organized. Consistent organizational work led to the identification and formation of a group of teachers interested in promoting this topic;
The presence of a bright, charismatic leader, such as Vladimir Valentinovich Voevodin - Doctor of Physical and Mathematical Sciences, Professor, Corresponding Member of the Russian Academy of Sciences, Deputy Director of the Research Computing Center of Moscow State University;
Interest and support (including material) from the Russian representative office of Intel and the strategic development manager of Intel, Igor Olegovich Odintsov.
The disadvantage of the “supercomputer” approach is that it narrows the scope of parallel computing. Supercomputers themselves are, as a rule, inaccessible to schoolchildren (unless in large cities they can be seen on excursions). The tasks they are aimed at solving are too complex for schoolchildren and, in most cases, do not have immediate practical significance and are not of practical interest.
A natural extension of the supercomputing field is the study of parallel programming. Currently, to execute parallel programs it is not at all necessary to have a supercomputer. A multi-core processor or video card with a set of graphics accelerators is enough. And this is already available to almost everyone. Among the works in this direction, we note the candidate’s dissertation of M.A. Sokolovskaya on the methodology of teaching future computer science teachers the basics of parallel programming and the experience of E.Yu. Kiseleva on mastering CUDA technology by schoolchildren.
According to the author of this article, focusing on supercomputers and parallel programming significantly impoverishes and complicates the topic of parallel computing and distracts students from many important and accessible issues. The purpose of the topic “parallel
computing” in high school is not teaching “real” parallel programming (studying relevant language constructs, programming languages and technologies), but familiarizing students with the corresponding set of concepts and understanding the features of parallel work. The world around and inside us is a complex parallel system. And this system itself provides a lot of material for mastering the concepts and mechanisms of parallelism. No complex artificial structures such as MPI and OpenMP technologies are needed for this. School computer science should foster thinking in a “parallel way.” And then let the university incorporate professional knowledge, skills, and abilities into this thinking. At school, it makes sense to focus not on getting to know supercomputers and studying parallel programming, but on mastering the mechanisms of “joint activity” that are constantly and widely used in life. The course proposes to cover the following questions:
1) Collaboration of several executors (digging a ditch with several diggers) and parallelization “inside” one executor in the presence of several processing devices (reading and eating an apple). In computer science, this will be a multi-machine complex and a multi-core processor.
2) Types of parallelism: true parallelism and pseudo-parallelism (one processor executes several programs in parts).
3) Performers of the same type (diggers) and different types (tank crew).
4) Works of the same type and different types.
5) The ratio of “executors - jobs”: 1 performer - 1 job, 1 performer - N jobs (pseudo-parallel execution or true parallelism in the presence of several processing devices for various works), N performers - 1 work, N performers - N works.
6) Coordination of the activities of performers. Types of approval: by parts of work, by time, by results of activities, by resources.
7) Resources. Resources are shared and non-shared, consumable and reusable. Recycling of consumed resources (“garbage collection” in the broad sense).
8) Performing the same work by one performer and a group of performers. Dependence of work speed on the number of performers. Dependence of the cost of work on the number of performers. Nonlinear increase in work speed with an increase in the number of performers. Critical path. Optimal number of performers. Optimal loading of performers. Optimal procedure. Load balancing.
9) Competition between performers for resources. Blocking. Clinch (deadlock).
10) Mechanisms for coordinating the actions of performers.
11) Pseudo-parallel execution of processes on a computer (division of one resource - the processor) between executor-processes.
12) Suitability of algorithms for parallelization. Possible degree of parallelization. The existence of algorithms that cannot be parallelized.
Please note that the above list represents the private opinion of the author of the article and is open for discussion, addition and correction. Moreover, in the author’s opinion, it would be very useful for the “supercomputer community” to formulate a “social order” for the school: what kind of knowledge and skills it wants to see in school graduates. How should a graduate of the “supercomputer world” school differ from a graduate of today? If there is an order, there will be a result. Fresh example. On the first day of Russian Supercomputing Days-2015, two reports voiced the idea that the speed of modern supercomputers is determined not by the power of processors (which is the focus of public attention), but by the speed of RAM. It is this that becomes the bottleneck, the throughput of which determines the productivity of the entire system. As a result, on the second day of the conference, participants in the teacher’s master class tested a game invented by the author of this article, demonstrating the interaction of the central processor, RAM and cache memory. The order and form of presentation of the material is an open question.
The material should be demonstrated using examples not related to the operation of a computer. Performers must manipulate material objects.
As much of the training as possible should be in the nature of business (organizational and activity) games.
Fulfilling these requirements will make it easier to understand the material being studied. This will be useful both when using this technique in computer science lessons at school (including elementary!), and when teaching adults: computer science teachers and students. A schoolchild, a school teacher, a student of a non-core specialty will be able to stop at the level of familiarization and understanding. The professional student will have to take the next step and move from acquaintance to studying these mechanisms at a professional level. But this is already a step beyond the methods of initial familiarization with the topic.
The author of this article began work on preparing a methodology for studying parallel computing in 2013 during the preparation of the TRIZformashka-2013 competition and continued in subsequent years.
(“TRIZformashka” is an interregional Internet competition in computer science, system analysis and TRIZ. Held annually in the second half of March. Age of participants - from first grade to fourth year. Geography - from Vladivostok to Riga. Average number of participants - 100 teams (300 people .), maximum - 202 teams (more than 600 people). The competition website is www.trizformashka.ru.) Then, in 2013, the goal of the work was formulated as follows:
1. Within two to three years, prepare a description of performers, a set of games and tasks related to parallel computing;
2. Offer them (in parts, annually) to the participants of the competition;
3. Analyze their reaction (estimate the number of solvers, their age, the success of the solution, typical mistakes, detected inaccuracies in the formulation of tasks, etc.). The TRIZformashka competition turned out to be a convenient tool for debugging problems, since
made it possible to obtain reactions from all ages (from first grade to fourth year), from different regions, from different educational institutions.
Over the past years, the following set of methodological tools and platforms for their testing have been prepared.
1. Tasks on parallelism, starting from 2013, were included in the “TRIZformashka” competition (starting from 2013, the competition has the subtitle “Parallel Computing”). A list of task types is given below;
2. A chapter on parallelism has been prepared for new version computer science textbook for 4th grade. The material was tested in 3rd and 4th grades of Lyceum No. 10 in Perm;
3. Developed and used in the TRIZformashka competition since 2014 computer game"Tank crew";
4. A number of games have been developed and tested, which reflect the following issues:
Coordination of the activities of performers. Various types of approval;
Performing the same work by one performer and a group of performers. Dependence of work speed on the number of performers. Nonlinear increase in work speed with an increase in the number of performers. Critical path. Optimal number of performers. Optimal loading of performers. Optimal procedure;
Resources. Shared and non-shared resources;
Competition between performers for resources. Blocking. Clinch (deadlock). The following types of problems were proposed and tested:
1. Tasks on types of approval. (What types of coordination exist in the school cafeteria?);
2. Game "Tank Crew". Assignment to build a parallel algorithm;
3. Performer “Construction”. At the same time, working teams build a structure from horizontal and vertical beams. Tasks include tasks for the execution of the specified algorithm, for the development of a new algorithm, for searching for errors in a given algorithm, for researching algorithms (comparing construction times using different algorithms, comparing construction costs, assessing the possibility of saving by redistributing labor, etc.);
4. Competition for resources. Three little pigs each cook their own lunch. For each piglet it is indicated what dishes he prepares, what resources (equipment, utensils, etc.) he needs for this and for how long these resources should be used. It is necessary to draw up a work schedule for each piglet, if he cooks alone in the kitchen, if they cook in pairs, if all three cook at once. Cooking time should be minimized;
5. Network diagram. A network diagram is given. It is required to depict (schematically) the structure that will be built, determine how many days it will take for construction with a particular number of teams, what part of the work will be completed by a certain time;
6. Tiered-parallel forms. Planning work according to various criteria. The work assignment, worker productivity, and payment rules are given. It is necessary to determine the number of workers needed to complete the work in a given time, determine the period of work for a given number of workers, determine the number of workers needed to minimize the cost of work;
7. Gantt charts. The text describes the work plan for the reconstruction of the workshop: duration and mutual sequence of actions, required workers. It is necessary to determine the deadline for the completion of the object, the change in the deadline due to certain changes in the workforce, and the list of workers involved on a specific date.
8. Coordination of repetitive work. Let the task be given in minimum term produce a batch of devices, provided that each device must be processed on different equipment; there are different amounts of equipment with different productivity. It is necessary to plan the start and operation time of each equipment and minimize downtime.
Today we have the following results:
1. An approach has been formulated for studying the topic of “parallel computing”: to go not from the problems of computer science, but “from life”, to focus on “joint activity”;
2. A list of questions has been formulated that are proposed to be reflected in the initial course of parallel computing;
3. Some classes of problems are formulated. Based on the accumulated experience, you can evaluate what kind of problems should be invented;
4. A set of problems of the named classes has been prepared. The problems were tested in the TRIZformashka competitions in 2013, 2014, 2015. and/or in elementary school (in classes with students of the third and fourth grades of Lyceum No. 10 in Perm);
5. A set of business games has been prepared. The games have been tested in primary schools and at a number of events for teachers. In particular, they were presented at the school track of the Summer Supercomputer Academy of Moscow State University in 2014, at a master class for teachers at Russian Supercomputing Days-2015, at several other conferences (including at the IT-education-2015 conference of the APKIT association) and other events for computer science teachers;
6. A set of texts about parallelism has been prepared for a fourth grade textbook. The texts were tested at Lyceum No. 10 in Perm;
7. The computer game “Tank Crew” has been prepared. The game was tested in the TRIZformashka competitions in 2014 and 2015;
8. The TRIZformashka competition has proven itself as an approbation platform;
9. The task of “castling” in the process of teaching algorithmization is formulated: immediately teach parallel programming, presenting a sequential algorithm as part of a parallel one. There are thoughts on how this idea can be implemented. There is an opportunity to try out these ideas during the current school year (for students in grades 4-5);
10. There is a need, desire and opportunity to continue working.
Literature
1. Algorithms: grades 5-7: Textbook and problem book for general education. educational institutions /A.K. Zvonkin, A.G. Kulakov, S.K. Lando, A.L. Semenov, A.Kh. Shen. - M.: Bustard, 1996.
2. Bosova L.L. Parallel algorithms in primary and secondary schools. //Informatics at school. 2015, no. 2. P.24-27.
3. Voevodin V.V. Computational mathematics and the structure of algorithms: Lecture 10 about why it is difficult to solve problems on parallel architecture computing systems and what additional information you need to know. to successfully overcome these difficulties: a textbook. M.: MSU Publishing House 2010.
4. Gavrilova I.V. First trip to the “parallel world”. //Informatics at school. 2015, No. 6. P.16-19.
5. Dieter M.L., Plaksin M.A. Parallel computing in school computer science. Game "Construction". //Informatics at school: past, present and future.: materials of the All-Russian. scientific method. conf. on the use of ICT in education, February 6-7, 2014 /Perm. state national research univ. - Perm, 2014. - P.258-261.
6. Ivanova N.G., Plaksin M.A., Rusakova O.L. TRIZformashka. //Computer science. N05 Retrieved 10/10/2015.
14. Plaksin M.A. Computer science: textbook for 4th grade: 2 hours / M.A.Plaksin, N.G.Ivanova, O.L.Rusakova. - M.: BINOM. Knowledge Laboratory, 2012.
15. Plaksin M.A. About the method of initial acquaintance with parallel computing in high school. //Informatics at school: past, present and future.: materials of the All-Russian. scientific method. conf. on the use of ICT in education, February 6-7, 2014 /Perm. state national research univ. - Perm, 2014. - P.256-258.
16. Plaksin M.A. A set of business games for introducing parallel computing in elementary school. //Teaching information technologies in the Russian Federation: materials of the Thirteenth Open All-Russian Conference “IT-0education-2015” (Perm, May 14-15, 2015). Perm State National Research University, - Perm, 2015. P.60-62.
17. Plaksin M.A., Ivanova N.G., Rusakova O.L. A set of tasks for getting acquainted with parallel computing in the TRIZformashka competition. //Teaching information technologies in the Russian Federation: materials of the Thirteenth Open All-Russian Conference “IT Education-2015” (Perm, May 14-15, 2015). Perm State National Research University, - Perm, 2015. pp. 232-234.
18. Sokolovskaya M.A. Methodological system for teaching the basics of parallel programming to future computer science teachers.: abstract. dis. ...cand. ped. Sciences, Krasnoyarsk, 2012.
The current version of the page has not yet been verified
The current version of the page has not yet been verified by experienced participants and may differ significantly from the version verified on October 5, 2014; checks are required.
Parallel Computing- a method of organizing computer computing, in which programs are developed as a set of interacting computing processes running in parallel (simultaneously). The term covers a set of issues of parallelism in programming, as well as the creation of efficient hardware implementations. The theory of parallel computing constitutes a branch of applied theory of algorithms.
Exist various ways implementation of parallel computing. For example, each computing process may be implemented as an operating system process, or computing processes may be a collection of threads of execution within a single OS process. Parallel programs can be physically executed either sequentially on a single processor - alternating in turn the steps of each computational process, or in parallel - allocating one or more processors (located nearby or distributed in a computer network) to each computational process.
The main difficulty in designing parallel programs is to ensure the correct sequence of interactions between different computing processes, as well as the coordination of resources shared between processes.
In some parallel programming systems, data transfer between components is hidden from the programmer (for example, using a promise mechanism), while in others it must be specified explicitly. Explicit interactions can be divided into two types:
Message-passing parallel systems are often easier to understand than shared memory systems and are generally considered a superior method of parallel programming. There is a wide range of mathematical theories for the study and analysis of message passing systems, including the actor model and various types of process calculus. Messaging can be efficiently implemented on symmetric multiprocessors with or without shared coherent memory.
Distributed memory parallelism and message passing parallelism have different performance characteristics. Typically (but not always), the overhead of process memory and task switching time is lower for message-passing systems, but message passing is more expensive than procedure calls. These differences are often overshadowed by other factors that affect performance.
The concept of parallel computing
FUNDAMENTALS OF PARALLEL COMPUTING
Lecture No. 6
Under parallel or concurrent computations you can understand problem solving processes in which several computational operations can be performed simultaneously at the same time
Parallel computing forms the basis of supercomputing technologies and high-performance computing
Parallel processing
If a certain device performs one operation per unit of time, then it will perform a thousand operations in a thousand units. If we assume that there are five identical independent devices capable of operating simultaneously, then a system of five devices can perform the same thousand operations not in a thousand, but in two hundred units of time.
Similarly, a system of N devices will perform the same work in 1000/N units of time. Similar analogies can be found in life: if one soldier digs up a garden in 10 hours, then a company of fifty soldiers with the same abilities, working simultaneously, will cope with the same work in 12 minutes - the principle of parallelism in action!
The pioneer in parallel processing of data streams was Academician A.A. Samarsky, who performed the calculations necessary to simulate nuclear explosions in the early 50s. Samarsky solved this problem by seating several dozen young ladies with adding machines at tables. The young ladies transferred data to each other simply in words and put down the necessary numbers on adding machines. Thus, in particular, the evolution of the blast wave was calculated.
There was a lot of work, the young ladies were tired, and Alexander Andreevich walked among them and encouraged them. This, one might say, was the first parallel system. Although the calculations for the hydrogen bomb were carried out masterfully, their accuracy was very low, because there were few nodes in the grid used, and the calculation time was too long.
Conveyor processing
The idea of pipeline processing is to isolate individual stages of performing a general operation, and each stage, having completed its work, would pass the result to the next one, while simultaneously receiving a new portion of input data. We get an obvious gain in processing speed by combining previously spaced operations.
Let's assume that there are five micro-operations in an operation, each of which is performed in one unit of time. If there is one indivisible serial device, then it will process 100 pairs of arguments in 500 units. If each micro-operation is separated into a separate stage (or otherwise called a stage) of a conveyor device, then on the fifth unit of time, at different stages of processing of such a device, the first five pairs of arguments will be located, and the entire set of one hundred pairs will be processed in 5 + 99 = 104 units time - acceleration compared to a serial device is almost five times (according to the number of conveyor stages).
Models of parallel computers (Flynn classification)
· “One command stream - one data stream” (SISD - “Single Instruction Single Data”)
Refers to von Neumann architecture. SISD computers are ordinary, “traditional” sequential computers, in which only one operation is performed on one data element (numeric or some other value) at any given time. Most modern personal computers fall into this category.
· "One command stream - many data streams" (SIMD - "Single Instruction - Multiple Data")
SIMD (Single Instruction, Multiple Data)- a principle of computer computing that allows for parallelism at the data level. SIMD computers consist of one command processor (control module), called a controller, and several data processing modules, called processing elements. The control module receives, analyzes and executes commands.
If data is encountered in the command, the controller sends a command to all processor elements, and this command is executed on several or all processor elements. Each processing element has its own memory for storing data. One of the advantages of this architecture is that in this case the calculation logic is implemented more efficiently. SIMD processors are also called vector processors.
· “Many command streams - one data stream” (MISD - “Multiple Instruction - Single Data”)
There are practically no computers of this class and it is difficult to give an example of their successful implementation. One of the few is a systolic array of processors, in which the processors are located at the nodes of a regular lattice, the role of edges of which is played by interprocessor connections. All processor elements are controlled by a common clock generator. In each operating cycle, each processing element receives data from its neighbors, executes one command and transmits the result to its neighbors.
Arrays of PEs with direct connections between nearby PEs are called systolic. Such arrays are extremely efficient, but each of them is focused on solving a very narrow class of problems. Let's consider how you can build a systolic array to solve a certain problem. Let, for example, you want to create a device for calculating a matrix D=C+AB, Where
Here all matrices are band matrices of order n. Matrix A has one diagonal above and two diagonals below the main one; matrix B- one diagonal below and two diagonals above the main one; matrix C three diagonals above and below the main one. Let each PE be able to perform a scalar operation c+ab and simultaneously transmit data. Each PE, therefore, must have three inputs: a, b, c and three outputs: a, b, c. Input ( in) and weekends ( out) the data are related by relations
a out = a in , b out = b in , c out = c in + a in *b in ;
If at the time of the operation some data was not received, then we will assume that they are defined as zeros. Let us further assume that all PEs are located on a plane and each of them is connected to six neighboring ones. If you arrange the data as shown in the figure, the circuit will calculate the matrix D.
The array operates in clock cycles. During each clock cycle, all data is moved to neighboring nodes in the directions indicated by the arrows.
The figure shows the state of the systolic array at some point in time. In the next clock cycle, all data will move to one node and elements a11, b11, c11 will end up in one PE located at the intersection of the dashed lines. Therefore, the expression will be evaluated c11+a11b11.At the same clock, data a12 And b21 will come very close to the PE, located at the top of the systolic array.
In the next clock cycle, all data will again move one node in the direction of the arrows and will appear in the upper PE a12 And b21 and the result of the previous operation of the PE located below, i.e. c11+a11b11. Therefore, the expression will be evaluated c11+a11b11+a12b21. This is an element d11 matrices D.
Continuing the step-by-step examination of the process, we can verify that at the PE outputs corresponding to the upper boundary of the systolic array, matrix elements are periodically output after three steps D, while elements of the same diagonal appear at each output. In about 3n cycles, the calculation of the entire matrix will be completed D. In this case, the load on each systolic cell is asymptotically equal 1/3 .
"Many command streams - many data streams" (MIMD - "Multiple Instruction - Multiple Data")
This category of computer architectures is the richest if keep in mind examples of its successful implementations. It includes symmetrical parallel computing systems, workstations with multiple processors, workstation clusters, etc.
The enormous performance of parallel computers and supercomputers is more than offset by the difficulties of using them. Let's start with the simplest things. You have a program and access to, say, a 256-processor computer. What are you expecting? Yes, it is clear: you quite legitimately expect that the program will execute 256 times faster than on a single processor. But this is precisely what most likely will not happen.
 Order 343 mail. Order by Russian post. Consequences of failure to appear in court when summoned
Order 343 mail. Order by Russian post. Consequences of failure to appear in court when summoned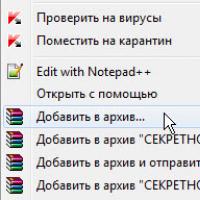 How to put a password on a folder on a Windows computer without and with programs
How to put a password on a folder on a Windows computer without and with programs Pluton – Free Bootstrap HTML5 One Page Template
Pluton – Free Bootstrap HTML5 One Page Template History of ZX Spectrum: Myths and reality New Spectrum
History of ZX Spectrum: Myths and reality New Spectrum Voice assistant Siri from Apple Siri functions on iPhone 6s
Voice assistant Siri from Apple Siri functions on iPhone 6s How to roll back to a previous version of iOS?
How to roll back to a previous version of iOS? Unlock iPad in four days
Unlock iPad in four days