Описание алгоритмов сортировки и сравнение их производительности. Как сделать сортировку данных в эксель
Реализация:
void insertionsort(int* l, int* r) { for (int *i = l + 1; i < r; i++) { int* j = i; while (j > l && *(j - 1) > *j) { swap(*(j - 1), *j); j--; } } }
Сортировка Шелла / Shellsort
Используем ту же идею, что и сортировка с расческой, и применим к сортировке вставками. Зафиксируем некоторое расстояние. Тогда элементы массива разобьются на классы – в один класс попадают элементы, расстояние между которыми кратно зафиксированному расстоянию. Отсортируем сортировкой вставками каждый класс. В отличие от сортировки расческой, неизвестен оптимальный набор расстояний. Существует довольно много последовательностей с разными оценками. Последовательность Шелла – первый элемент равен длине массива, каждый следующий вдвое меньше предыдущего. Асимптотика в худшем случае – O(n 2). Последовательность Хиббарда – 2 n - 1, асимптотика в худшем случае – O(n 1,5), последовательность Седжвика (формула нетривиальна, можете ее посмотреть по ссылке ниже) - O(n 4/3), Пратта (все произведения степеней двойки и тройки) - O(nlog 2 n). Отмечу, что все эти последовательности нужно рассчитать только до размера массива и запускать от большего от меньшему (иначе получится просто сортировка вставками). Также я провел дополнительное исследование и протестировал разные последовательности вида s i = a * s i - 1 + k * s i - 1 (отчасти это было навеяно эмпирической последовательностью Циура – одной из лучших последовательностей расстояний для небольшого количества элементов). Наилучшими оказались последовательности с коэффициентами a = 3, k = 1/3; a = 4, k = 1/4 и a = 4, k = -1/5.Несколько полезных ссылок:
Реализации:
void shellsort(int* l, int* r) { int sz = r - l; int step = sz / 2; while (step > < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } step /= 2; } } void shellsorthib(int* l, int* r) { int sz = r - l; if (sz <= 1) return; int step = 1; while (step < sz) step <<= 1; step >>= 1; step--; while (step >= 1) { for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } step /= 2; } } int steps; void shellsortsedgwick(int* l, int* r) { int sz = r - l; steps = 1; int q = 1; while (steps * 3 < sz) { if (q % 2 == 0) steps[q] = 9 * (1 << q) - 9 * (1 << (q / 2)) + 1; else steps[q] = 8 * (1 << q) - 6 * (1 << ((q + 1) / 2)) + 1; q++; } q--; for (; q > < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void shellsortpratt(int* l, int* r) { int sz = r - l; steps = 1; int cur = 1, q = 1; for (int i = 1; i < sz; i++) { int cur = 1 << i; if (cur > sz / 2) break; for (int j = 1; j < sz; j++) { cur *= 3; if (cur > sz / 2) break; steps = cur; } } insertionsort(steps, steps + q); q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void myshell1(int* l, int* r) { int sz = r - l, q = 1; steps = 1; while (steps < sz) { int s = steps; steps = s * 4 + s / 4; } q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void myshell2(int* l, int* r) { int sz = r - l, q = 1; steps = 1; while (steps < sz) { int s = steps; steps = s * 3 + s / 3; } q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } } void myshell3(int* l, int* r) { int sz = r - l, q = 1; steps = 1; while (steps < sz) { int s = steps; steps = s * 4 - s / 5; } q--; for (; q >= 0; q--) { int step = steps[q]; for (int *i = l + step; i < r; i++) { int *j = i; int *diff = j - step; while (diff >= l && *diff > *j) { swap(*diff, *j); j = diff; diff = j - step; } } } }
Сортировка деревом / Tree sort
Будем вставлять элементы в двоичное дерево поиска. После того, как все элементы вставлены достаточно обойти дерево в глубину и получить отсортированный массив. Если использовать сбалансированное дерево, например красно-черное, асимптотика будет равна O(nlogn) в худшем, среднем и лучшем случае. В реализации использован контейнер multiset.Реализация:
void treesort(int* l, int* r) {
multiset
Гномья сортировка / Gnome sort
Алгоритм похож на сортировку вставками. Поддерживаем указатель на текущий элемент, если он больше предыдущего или он первый - смещаем указатель на позицию вправо, иначе меняем текущий и предыдущий элементы местами и смещаемся влево.Реализация:
void gnomesort(int* l, int* r) { int *i = l; while (i < r) { if (i == l || *(i - 1) <= *i) i++; else swap(*(i - 1), *i), i--; } }
Сортировка выбором / Selection sort
На очередной итерации будем находить минимум в массиве после текущего элемента и менять его с ним, если надо. Таким образом, после i-ой итерации первые i элементов будут стоять на своих местах. Асимптотика: O(n 2) в лучшем, среднем и худшем случае. Нужно отметить, что эту сортировку можно реализовать двумя способами – сохраняя минимум и его индекс или просто переставляя текущий элемент с рассматриваемым, если они стоят в неправильном порядке. Первый способ оказался немного быстрее, поэтому он и реализован.Реализация:
void selectionsort(int* l, int* r) { for (int *i = l; i < r; i++) { int minz = *i, *ind = i; for (int *j = i + 1; j < r; j++) { if (*j < minz) minz = *j, ind = j; } swap(*i, *ind); } }
Пирамидальная сортировка / Heapsort
Развитие идеи сортировки выбором. Воспользуемся структурой данных «куча» (или «пирамида», откуда и название алгоритма). Она позволяет получать минимум за O(1), добавляя элементы и извлекая минимум за O(logn). Таким образом, асимптотика O(nlogn) в худшем, среднем и лучшем случае. Реализовывал кучу я сам, хотя в С++ и есть контейнер priority_queue, поскольку этот контейнер довольно медленный.Реализация:
template
Быстрая сортировка / Quicksort
Выберем некоторый опорный элемент. После этого перекинем все элементы, меньшие его, налево, а большие – направо. Рекурсивно вызовемся от каждой из частей. В итоге получим отсортированный массив, так как каждый элемент меньше опорного стоял раньше каждого большего опорного. Асимптотика: O(nlogn) в среднем и лучшем случае, O(n 2). Наихудшая оценка достигается при неудачном выборе опорного элемента. Моя реализация этого алгоритма совершенно стандартна, идем одновременно слева и справа, находим пару элементов, таких, что левый элемент больше опорного, а правый меньше, и меняем их местами. Помимо чистой быстрой сортировки, участвовала в сравнении и сортировка, переходящая при малом количестве элементов на сортировку вставками. Константа подобрана тестированием, а сортировка вставками - наилучшая сортировка, подходящая для этой задачи (хотя не стоит из-за этого думать, что она самая быстрая из квадратичных).Реализация:
void quicksort(int* l, int* r) { if (r - l <= 1) return; int z = *(l + (r - l) / 2); int* ll = l, *rr = r - 1; while (ll <= rr) { while (*ll < z) ll++; while (*rr > z) rr--; if (ll <= rr) { swap(*ll, *rr); ll++; rr--; } } if (l < rr) quicksort(l, rr + 1); if (ll < r) quicksort(ll, r); } void quickinssort(int* l, int* r) { if (r - l <= 32) { insertionsort(l, r); return; } int z = *(l + (r - l) / 2); int* ll = l, *rr = r - 1; while (ll <= rr) { while (*ll < z) ll++; while (*rr > z) rr--; if (ll <= rr) { swap(*ll, *rr); ll++; rr--; } } if (l < rr) quickinssort(l, rr + 1); if (ll < r) quickinssort(ll, r); }
Сортировка слиянием / Merge sort
Сортировка, основанная на парадигме «разделяй и властвуй». Разделим массив пополам, рекурсивно отсортируем части, после чего выполним процедуру слияния: поддерживаем два указателя, один на текущий элемент первой части, второй – на текущий элемент второй части. Из этих двух элементов выбираем минимальный, вставляем в ответ и сдвигаем указатель, соответствующий минимуму. Слияние работает за O(n), уровней всего logn, поэтому асимптотика O(nlogn). Эффективно заранее создать временный массив и передать его в качестве аргумента функции. Эта сортировка рекурсивна, как и быстрая, а потому возможен переход на квадратичную при небольшом числе элементов.Реализация:
void merge(int* l, int* m, int* r, int* temp) { int *cl = l, *cr = m, cur = 0; while (cl < m && cr < r) { if (*cl < *cr) temp = *cl, cl++; else temp = *cr, cr++; } while (cl < m) temp = *cl, cl++; while (cr < r) temp = *cr, cr++; cur = 0; for (int* i = l; i < r; i++) *i = temp; } void _mergesort(int* l, int* r, int* temp) { if (r - l <= 1) return; int *m = l + (r - l) / 2; _mergesort(l, m, temp); _mergesort(m, r, temp); merge(l, m, r, temp); } void mergesort(int* l, int* r) { int* temp = new int; _mergesort(l, r, temp); delete temp; } void _mergeinssort(int* l, int* r, int* temp) { if (r - l <= 32) { insertionsort(l, r); return; } int *m = l + (r - l) / 2; _mergeinssort(l, m, temp); _mergeinssort(m, r, temp); merge(l, m, r, temp); } void mergeinssort(int* l, int* r) { int* temp = new int; _mergeinssort(l, r, temp); delete temp; }
Сортировка подсчетом / Counting sort
Создадим массив размера r – l, где l – минимальный, а r – максимальный элемент массива. После этого пройдем по массиву и подсчитаем количество вхождений каждого элемента. Теперь можно пройти по массиву значений и выписать каждое число столько раз, сколько нужно. Асимптотика – O(n + r - l). Можно модифицировать этот алгоритм, чтобы он стал стабильным: для этого определим место, где должно стоять очередное число (это просто префиксные суммы в массиве значений) и будем идти по исходному массиву слева направо, ставя элемент на правильное место и увеличивая позицию на 1. Эта сортировка не тестировалась, поскольку большинство тестов содержало достаточно большие числа, не позволяющие создать массив требуемого размера. Однако она, тем не менее, пригодилась.Блочная сортировка / Bucket sort
(также известна как корзинная и карманная сортировка). Пусть l – минимальный, а r – максимальный элемент массива. Разобьем элементы на блоки, в первом будут элементы от l до l + k, во втором – от l + k до l + 2k и т.д., где k = (r – l) / количество блоков. В общем-то, если количество блоков равно двум, то данный алгоритм превращается в разновидность быстрой сортировки. Асимптотика этого алгоритма неясна, время работы зависит и от входных данных, и от количества блоков. Утверждается, что на удачных данных время работы линейно. Реализация этого алгоритма оказалась одной из самых трудных задач. Можно сделать это так: просто создавать новые массивы, рекурсивно их сортировать и склеивать. Однако такой подход все же довольно медленный и меня не устроил. В эффективной реализации используется несколько идей:1) Не будем создавать новых массивов. Для этого воспользуемся техникой сортировки подсчетом – подсчитаем количество элементов в каждом блоке, префиксные суммы и, таким образом, позицию каждого элемента в массиве.
2) Не будем запускаться из пустых блоков. Занесем индексы непустых блоков в отдельный массив и запустимся только от них.
3) Проверим, отсортирован ли массив. Это не ухудшит время работы, так как все равно нужно сделать проход с целью нахождения минимума и максимума, однако позволит алгоритму ускориться на частично отсортированных данных, ведь элементы вставляются в новые блоки в том же порядке, что и в исходном массиве.
4) Поскольку алгоритм получился довольно громоздким, при небольшом количестве элементов он крайне неэффективен. До такой степени, что переход на сортировку вставками ускоряет работу примерно в 10 раз.
Осталось только понять, какое количество блоков нужно выбрать. На рандомизированных тестах мне удалось получить следующую оценку: 1500 блоков для 10 7 элементов и 3000 для 10 8 . Подобрать формулу не удалось – время работы ухудшалось в несколько раз.
Реализация:
void _newbucketsort(int* l, int* r, int* temp) { if (r - l <= 64) { insertionsort(l, r); return; } int minz = *l, maxz = *l; bool is_sorted = true; for (int *i = l + 1; i < r; i++) { minz = min(minz, *i); maxz = max(maxz, *i); if (*i < *(i - 1)) is_sorted = false; } if (is_sorted) return; int diff = maxz - minz + 1; int numbuckets; if (r - l <= 1e7) numbuckets = 1500; else numbuckets = 3000; int range = (diff + numbuckets - 1) / numbuckets; int* cnt = new int; for (int i = 0; i <= numbuckets; i++) cnt[i] = 0; int cur = 0; for (int* i = l; i < r; i++) { temp = *i; int ind = (*i - minz) / range; cnt++; } int sz = 0; for (int i = 1; i <= numbuckets; i++) if (cnt[i]) sz++; int* run = new int; cur = 0; for (int i = 1; i <= numbuckets; i++) if (cnt[i]) run = i - 1; for (int i = 1; i <= numbuckets; i++) cnt[i] += cnt; cur = 0; for (int *i = l; i < r; i++) { int ind = (temp - minz) / range; *(l + cnt) = temp; cur++; cnt++; } for (int i = 0; i < sz; i++) { int r = run[i]; if (r != 0) _newbucketsort(l + cnt, l + cnt[r], temp); else _newbucketsort(l, l + cnt[r], temp); } delete run; delete cnt; } void newbucketsort(int* l, int* r) { int *temp = new int; _newbucketsort(l, r, temp); delete temp; }
Поразрядная сортировка / Radix sort
(также известна как цифровая сортировка). Существует две версии этой сортировки, в которых, на мой взгляд, мало общего, кроме идеи воспользоваться представлением числа в какой-либо системе счисления (например, двоичной).LSD (least significant digit):
Представим каждое число в двоичном виде. На каждом шаге алгоритма будем сортировать числа таким образом, чтобы они были отсортированы по первым k * i битам, где k – некоторая константа. Из данного определения следует, что на каждом шаге достаточно стабильно сортировать элементы по новым k битам. Для этого идеально подходит сортировка подсчетом (необходимо 2 k памяти и времени, что немного при удачном выборе константы). Асимптотика: O(n), если считать, что числа фиксированного размера (а в противном случае нельзя было бы считать, что сравнение двух чисел выполняется за единицу времени). Реализация довольно проста.Реализация:
int digit(int n, int k, int N, int M) { return (n >> (N * k) & (M - 1)); } void _radixsort(int* l, int* r, int N) { int k = (32 + N - 1) / N; int M = 1 << N; int sz = r - l; int* b = new int; int* c = new int[M]; for (int i = 0; i < k; i++) { for (int j = 0; j < M; j++) c[j] = 0; for (int* j = l; j < r; j++) c++; for (int j = 1; j < M; j++) c[j] += c; for (int* j = r - 1; j >= l; j--) b[--c] = *j; int cur = 0; for (int* j = l; j < r; j++) *j = b; } delete b; delete c; } void radixsort(int* l, int* r) { _radixsort(l, r, 8); }
MSD (most significant digit):
На самом деле, некоторая разновидность блочной сортировки. В один блок будут попадать числа с равными k битами. Асимптотика такая же, как и у LSD версии. Реализация очень похожа на блочную сортировку, но проще. В ней используется функция digit, определенная в реализации LSD версии.Реализация:
void _radixsortmsd(int* l, int* r, int N, int d, int* temp) { if (d == -1) return; if (r - l <= 32) { insertionsort(l, r); return; } int M = 1 << N; int* cnt = new int; for (int i = 0; i <= M; i++) cnt[i] = 0; int cur = 0; for (int* i = l; i < r; i++) { temp = *i; cnt++; } int sz = 0; for (int i = 1; i <= M; i++) if (cnt[i]) sz++; int* run = new int; cur = 0; for (int i = 1; i <= M; i++) if (cnt[i]) run = i - 1; for (int i = 1; i <= M; i++) cnt[i] += cnt; cur = 0; for (int *i = l; i < r; i++) { int ind = digit(temp, d, N, M); *(l + cnt) = temp; cur++; cnt++; } for (int i = 0; i < sz; i++) { int r = run[i]; if (r != 0) _radixsortmsd(l + cnt, l + cnt[r], N, d - 1, temp); else _radixsortmsd(l, l + cnt[r], N, d - 1, temp); } delete run; delete cnt; } void radixsortmsd(int* l, int* r) { int* temp = new int; _radixsortmsd(l, r, 8, 3, temp); delete temp; }
Битонная сортировка / Bitonic sort:
Идея данного алгоритма заключается в том, что исходный массив преобразуется в битонную последовательность – последовательность, которая сначала возрастает, а потом убывает. Ее можно эффективно отсортировать следующим образом: разобьем массив на две части, создадим два массива, в первый добавим все элементы, равные минимуму из соответственных элементов каждой из двух частей, а во второй – равные максимуму. Утверждается, что получатся две битонные последовательности, каждую из которых можно рекурсивно отсортировать тем же образом, после чего можно склеить два массива (так как любой элемент первого меньше или равен любого элемента второго). Для того, чтобы преобразовать исходный массив в битонную последовательность, сделаем следующее: если массив состоит из двух элементов, можно просто завершиться, иначе разделим массив пополам, рекурсивно вызовем от половинок алгоритм, после чего отсортируем первую часть по порядку, вторую в обратном порядке и склеим. Очевидно, получится битонная последовательность. Асимптотика: O(nlog 2 n), поскольку при построении битонной последовательности мы использовали сортировку, работающую за O(nlogn), а всего уровней было logn. Также заметим, что размер массива должен быть равен степени двойки, так что, возможно, придется его дополнять фиктивными элементами (что не влияет на асимптотику).Реализация:
void bitseqsort(int* l, int* r, bool inv) { if (r - l <= 1) return; int *m = l + (r - l) / 2; for (int *i = l, *j = m; i < m && j < r; i++, j++) { if (inv ^ (*i > *j)) swap(*i, *j); } bitseqsort(l, m, inv); bitseqsort(m, r, inv); } void makebitonic(int* l, int* r) { if (r - l <= 1) return; int *m = l + (r - l) / 2; makebitonic(l, m); bitseqsort(l, m, 0); makebitonic(m, r); bitseqsort(m, r, 1); } void bitonicsort(int* l, int* r) { int n = 1; int inf = *max_element(l, r) + 1; while (n < r - l) n *= 2; int* a = new int[n]; int cur = 0; for (int *i = l; i < r; i++) a = *i; while (cur < n) a = inf; makebitonic(a, a + n); bitseqsort(a, a + n, 0); cur = 0; for (int *i = l; i < r; i++) *i = a; delete a; }
Timsort
Гибридная сортировка, совмещающая сортировку вставками и сортировку слиянием. Разобьем элементы массива на несколько подмассивов небольшого размера, при этом будем расширять подмассив, пока элементы в нем отсортированы. Отсортируем подмассивы сортировкой вставками, пользуясь тем, что она эффективно работает на отсортированных массивах. Далее будем сливать подмассивы как в сортировке слиянием, беря их примерно равного размера (иначе время работы приблизится к квадратичному). Для этого удобного хранить подмассивы в стеке, поддерживая инвариант - чем дальше от вершины, тем больше размер, и сливать подмассивы на верхушке только тогда, когда размер третьего по отдаленности от вершины подмассива больше или равен сумме их размеров. Асимптотика: O(n) в лучшем случае и O(nlogn) в среднем и худшем случае. Реализация нетривиальна, твердой уверенности в ней у меня нет, однако время работы она показала довольно неплохое и согласующееся с моими представлениями о том, как должна работать эта сортировка.Подробнее timsort описан здесь:
Реализация:
void _timsort(int* l, int* r, int* temp) {
int sz = r - l;
if (sz <= 64) {
insertionsort(l, r);
return;
}
int minrun = sz, f = 0;
while (minrun >= 64) {
f |= minrun & 1;
minrun >>= 1;
}
minrun += f;
int* cur = l;
stack
Тестирование
Железо и система
Процессор: Intel Core i7-3770 CPU 3.40 GHzОЗУ: 8 ГБ
Тестирование проводилось на почти чистой системе Windows 10 x64, установленной за несколько дней до запуска. Использованная IDE – Microsoft Visual Studio 2015.
Тесты
Все тесты поделены на четыре группы. Первая группа – массив случайных чисел по разным модулям (10, 1000, 10 5 , 10 7 и 10 9). Вторая группа – массив, разбивающийся на несколько отсортированных подмассивов. Фактически брался массив случайных чисел по модулю 10 9 , а далее отсортировывались подмассивы размера, равного минимуму из длины оставшегося суффикса и случайного числа по модулю некоторой константы. Последовательность констант – 10, 100, 1000 и т.д. вплоть до размера массива. Третья группа – изначально отсортированный массив случайных чисел с некоторым числом «свопов» - перестановок двух случайных элементов. Последовательность количеств свопов такая же, как и в предыдущей группе. Наконец, последняя группа состоит из нескольких тестов с полностью отсортированным массивом (в прямом и обратном порядке), нескольких тестов с исходным массивом натуральных чисел от 1 до n, в котором несколько чисел заменены на случайное, и тестов с большим количеством повторений одного элемента (10%, 25%, 50%, 75% и 90%). Таким образом, тесты позволяют посмотреть, как сортировки работают на случайных и частично отсортированных массивах, что выглядит наиболее существенным. Четвертая группа во многом направлена против сортировок с линейным временем работы, которые любят последовательности случайных чисел. В конце статьи есть ссылка на файл, в котором подробно описаны все тесты.Размер входных данных
Было бы довольно глупо сравнивать, например, сортировку с линейным временем работы и квадратичную, и запускать их на тестах одного размера. Поэтому каждая из групп тестов делится еще на четыре группы, размера 10 5 , 10 6 , 10 7 и 10 8 элементов. Сортировки были разбиты на три группы, в первой – квадратичные (сортировка пузырьком, вставками, выбором, шейкерная и гномья), во второй – нечто среднее между логарифмическим временем и квадратом, (битонная, несколько видов сортировки Шелла и сортировка деревом), в третьей все остальные. Кого-то, возможно, удивит, что сортировка деревом попала не в третью группу, хотя ее асимптотика и O(nlogn), но, к сожалению, ее константа очень велика. Сортировки первой группы тестировались на тестах с 10 5 элементов, второй группы – на тестах с 10 6 и 10 7 , третьей – на тестах с 10 7 и 10 8 . Именно такие размеры данных позволяют как-то увидеть рост времени работы, при меньших размерах слишком велика погрешность, при больших алгоритм работает слишком долго (или же недостаток оперативной памяти). С первой группой я не стал заморачиваться, чтобы не нарушать десятикратное увеличение (10 4 элементов для квадратичных сортировок слишком мало), в конце концов, сами по себе они представляют мало интереса.Как проводилось тестирование
На каждом тесте было производилось 20 запусков, итоговое время работы – среднее по получившимся значениям. Почти все результаты были получены после одного запуска программы, однако из-за нескольких ошибок в коде и системных глюков (все же тестирование продолжалось почти неделю чистого времени) некоторые сортировки и тесты пришлось впоследствии перетестировать.Тонкости реализации
Возможно, кого-то удивит, что в реализации самого процесса тестирования я не использовал указатели на функции, что сильно сократило бы код. Оказалось, что это заметно замедляет работу алгоритма (примерно на 5-10%). Поэтому я использовал отдельный вызов каждой функции (это, конечно, не отразилось бы на относительной скорости, но… все же хочется улучшить и абсолютную). По той же причине были заменены векторы на обычные массивы, не были использованы шаблоны и функции-компараторы. Все это более актуально для промышленного использования алгоритма, нежели его тестирования.Результаты
Все результаты доступны в нескольких видах – три диаграммы (гистограмма, на которой видно изменение скорости при переходе к следующему ограничению на одном типе тестов, график, изображающий то же самое, но иногда более наглядно, и гистограмма, на которой видно, какая сортировка лучше всего работает на каком-то типе тестов) и таблицы, на которых они основаны. Третья группа была разделена еще на три части, а то мало что было бы понятно. Впрочем, и так далеко не все диаграммы удачны (в полезности третьего типа диаграмм я вообще сильно сомневаюсь), но, надеюсь, каждый сможет найти наиболее подходящую для понимания.Поскольку картинок очень много, они скрыты спойлерами. Немного комментариев по поводу обозначений. Сортировки названы так, как выше, если это сортировка Шелла, то в скобочках указан автор последовательности, к названиям сортировок, переходящих на сортировку вставками, приписано Ins (для компактности). В диаграммах у второй группы тестов обозначена возможная длина отсортированных подмассивов, у третьей группы - количество свопов, у четвертой - количество замен. Общий результат рассчитывался как среднее по четырем группам.
Первая группа сортировок
Массив случайных чисел
Таблицы



Совсем скучные результаты, даже частичная отсортированность при небольшом модуле почти незаметна.
Таблицы




Уже гораздо интереснее. Обменные сортировки наиболее бурно отреагировали, шейкерная даже обогнала гномью. Сортировка вставками ускорилась только под самый конец. Сортировка выбором, конечно, работает совершенно также.
Свопы
Таблицы





Здесь наконец-то проявила себя сортировка вставками, хотя рост скорости у шейкерной примерно такой же. Здесь проявилась слабость сортировки пузырьком - достаточно одного свопа, перемещающего маленький элемент в конец, и она уже работает медленно. Сортировка выбором оказалась почти в конце.
Изменения в перестановке
Таблицы





Группа почти ничем не отличается от предыдущей, поэтому результаты похожи. Однако сортировка пузырьком вырывается вперед, так как случайный элемент, вставленный в массив, скорее всего будет больше всех остальных, то есть за одну итерацию переместится в конец. Сортировка выбором стала аутсайдером.
Повторы
Таблицы





Здесь все сортировки (кроме, конечно, сортировки выбором) работали почти одинаково, ускоряясь по мере увеличении количества повторов.
Итоговые результаты

За счет своего абсолютного безразличия к массиву, сортировка выбором, работавшая быстрее всех на случайных данных, все же проиграла сортировке вставками. Гномья сортировка оказалась заметно хуже последней, из-за чего ее практическое применение сомнительно. Шейкерная и пузырьковая сортировки оказались медленнее всех.
Вторая группа сортировок
Массив случайных чисел
Таблицы, 1е6 элементов




Сортировка Шелла с последовательностью Пратта ведет себя совсем странно, остальные более менее ясно. Сортировка деревом любит частично отсортированные массивы, но не любит повторов, возможно, поэтому самое худшее время работы именно посередине.
Таблицы, 1е7 элементов




Все как прежде, только Шелл с Праттом усилился на второй группе из-за отсортированности. Также становится заметным влияние асимптотики - сортировка деревом оказывается на втором месте, в отличие от группы с меньшим числом элементов.
Частично отсортированный массив
Таблицы, 1е6 элементов




Здесь понятным образом ведут себя все сортировки, кроме Шелла с Хиббардом, который почему-то не сразу начинает ускоряться.
Таблицы, 1е7 элементов




Здесь все, в общем, как и прежде. Даже асимптотика сортировки деревом не помогла ей вырваться с последнего места.
Свопы
Таблицы, 1е6 элементов





Таблицы, 1е7 элементов




Здесь заметно, что у сортировок Шелла большая зависимость от частичной отсортированности, так как они ведут себя практически линейно, а остальные две только сильно падают на последних группах.
Изменения в перестановке
Таблицы, 1е6 элементов




Таблицы, 1е7 элементов




Здесь все похоже на предыдущую группу.
Повторы
Таблицы, 1е6 элементов




Опять все сортировки продемонстрировали удивительную сбалансированность, даже битонная, которая, казалось бы, почти не зависит от массива.
Таблицы, 1е7 элементов




Ничего интересного.
Итоговые результаты


Убедительное первое место заняла сортировка Шелла по Хиббарду, не уступив ни в одной промежуточной группе. Возможно, стоило ее отправить в первую группу сортировок, но… она слишком слаба для этого, да и тогда почти никого не было бы в группе. Битонная сортировка довольно уверенно заняла второе место. Третье место при миллионе элементах заняла другая сортировка Шелла, а при десяти миллионах сортировка деревом (асимптотика сказалась). Стоит обратить внимание, что при десятикратном увеличении размера входных данных все алгоритмы, кроме древесной сортировки, замедлились почти в 20 раз, а последняя всего лишь в 13.
Третья группа сортировок
Массив случайных чисел
Таблицы, 1е7 элементов











Таблицы, 1е8 элементов











Почти все сортировки этой группы имеют почти одинаковую динамику. Почему же почти все сортировки ускоряются, когда массив частично отсортирован? Обменные сортировки работают быстрее потому, что надо делать меньше обменов, в сортировке Шелла выполняется сортировка вставками, которая сильно ускоряется на таких массивах, в пирамидальной сортировке при вставке элементов сразу завершается просеивание, в сортировке слиянием выполняется в лучшем случае вдвое меньше сравнений. Блочная сортировка работает тем лучше, чем меньше разность между минимальным и максимальным элементом. Принципиально отличается только поразрядная сортировка, которой все это безразлично. LSD-версия работает тем лучше, чем больший модуль. Динамика MSD-версия мне не ясна, то, что она сработала быстрее чем LSD удивило.
Частично отсортированный массив
Таблицы, 1е7 элементов











Таблицы, 1е8 элементов











Здесь все тоже довольно понятно. Стало заметен алгоритм Timsort, на него отсортированность действует сильнее, чем на остальные. Это позволило этому алгоритму почти сравняться с оптимизированной версией быстрой сортировки. Блочная сортировка, несмотря на улучшение времени работы при частичной отсортированности, не смогла обогнать поразрядную сортировку.
Сортировка в Эксель – это встроенная функция, с помощью которой пользователь сможет расположить данные в столбцах на листе в удобном порядке для их последующего анализа.
Вы сможете отсортировать информацию в алфавитном порядке, по возрастанию или убыванию значений, по дате или по значкам, по цвету текста или ячейки. Именно об этом и пойдет речь в данной статье.
Чисел
Здесь все достаточно просто. Для примера возьмем следующую таблицу. Сделаем в ней сортировку данных по столбцу С . Для этого выделяем его и на вкладке «Главная» кликаем на кнопочку «Сортировка и фильтр» . В следующем меню выберите или «… от минимального к максимальному» , или «… от максимального к минимальному» . Выберем второй вариант.
Теперь у нас данные в С размещены в порядке убывания.

У меня столбец С расположен между двумя другими, которые заполнены данными. В этом случае, Excel считает, что выделенный столбец – это часть таблицы (и считает правильно). В результате появилось следующее сообщение. Поскольку мне нужно сделать сортировку конкретно для Класса, выделяю маркером пункт «… в пределах указанного выделения» и нажимаю «Сортировка» .

По алфавиту
Она делается по тому же принципу, как было описано выше. Выделяем нужный диапазон, и нажимаем кнопочку «Сортировка и фильтр» . В выпадающем меню пункты изменились. Выберите или от «А до Я» , или от «Я до А» .

Список имен в примере отсортирован по алфавиту.

По дате
Чтобы отсортировать даты в Эксель, сначала обратите внимание, какой формат установлен для тех ячеек, в которых они записаны. Выделите их и на вкладке «Главная» посмотрите на группу «Число» . Лучше всего подойдет или формат «Дата» , краткий или длинный, или «(все форматы)» – дата может быть записана различными способами: ДД.ММ.ГГГГ, ДД.МММ, МММ.ГГ.

Этот момент очень важен, так как в противном случае, даты могут быть отсортированы просто по возрастанию первых двух чисел, или по месяцам в алфавитном порядке.
После этого выделяем нужный диапазон ячеек и жмем на кнопочку «Сортировка и фильтр» . В меню можно выбрать или «от старых к новым» , или «от новых к старым» .

По цвету ячейки или текста
Этот способ можно использовать, когда в таблице Excel текст в ячейках или сами ячейки закрашены в различный цвет. Для примера возьмем столбец из чисел, закрашенных разными цветами. Отсортируем его, чтобы сначала шли числа, закрашенные в красный, затем зеленый и черный цвет.
Выделяем весь диапазон, кликаем на кнопочку «Сортировка и фильтр» и выбираем из меню «Настраиваемая…» .

В следующем окне, уберите галочку с поля , если Вы выделили их без верхней строки, которая является шапкой таблицы. Затем выбираем столбец, по которому будем сортировать, в примере это «I» . В разделе «Сортировка» из выпадающего списка выбираем «Цвет шрифта» . В разделе порядок выбираем «красный цвет» – «Сверху» . Это мы отсортировали числа красного цвета.

Теперь нужно, чтобы в столбце шли числа зеленого цвета. Нажмите на кнопочку «Добавить уровень» . Все настройки те же, только выберите «зеленый цвет» . Нажмите «ОК» .

Наш столбец отсортирован следующим образом.
Как видите, числа идут не по порядку. Давайте отсортируем числа в порядке возрастания. Выделяем столбец, нажимаем «Сортировка и фильтр» – «Настраиваемая …» . В открывшемся окне нажмите на кнопку «Добавить уровень» . Столбец остается «I» , в следующем поле выбираем по «Значению» , порядок «По возрастанию» . Нажмите «ОК» .

Теперь наш столбец отсортирован и по цвету текста и в порядке возрастания данных.
Аналогичным образом сортируются данные и по цвету ячейки, только в разделе «Сортировка» выбирайте из списка «Цвет ячейки» .
Таблицы
Если у Вас есть таблица, в которой нужно выполнить сортировку сразу по нескольким столбцам, делаем следующее. Выделяем весь диапазон ячеек таблицы вместе с шапкой. Кликаем по кнопочке «Сортировка и фильтр» и выбираем «Настраиваемая …» .

Давайте отсортируем класс в порядке возрастания, и таким же образом средний бал.
В окне сортировки ставим галочку в поле «Мои данные содержат заголовки» . В разделе «Столбец» выбираем из списка «Класс» , сортировка по «Значению» , а порядок «По возрастанию» .
Чтобы сделать все тоже самое по среднему балу, нажмите на кнопочку «Добавить уровень» . В разделе «Столбец» выбираем «Средн.бал» . Нажмите «ОК» .

Данные в таблице отсортированы.

Теперь в столбце «Имя» закрасим ячейки с мальчиками в синий цвет, ячейки с девочками в розовый. Чтобы не делать это для каждой ячейки в отдельности, прочтите статью, как выделить ячейки в Excel – в ней написано, как выделить несмежные ячейки.
Выполним сортировку этого столбца по цвету ячейки: сначала будут девочки, потом мальчики. Снова выделяем всю таблицу, жмем «Сортировка» – «Настраиваемая …» .

В открывшемся окне уже есть два уровня, которые мы сделали раньше. Эти уровни имеют приоритет – у первого самый большой, у второго меньше и так далее. То есть, если мы хотим, чтобы сначала выполнилась сортировка данных в таблице девочки/мальчики, затем по классу, а затем по среднему балу – нужно в таком порядке и расставить уровни.
Нажимаем на кнопку «Добавить уровень» . В разделе «Столбец» выбираем «Имя» , сортировка – «Цвет ячейки» , порядок – «розовый» , «Сверху» .

Теперь с помощью стрелочек перемещаем данную строку наверх списка. Нажмите «ОК» .

Таблица с отсортированными данными выглядит следующим образом.

Сортировка данных - неотъемлемая часть их анализа. Вам может потребоваться расположить имена в списке по алфавиту, составить список складских запасов и отсортировать его по убыванию или упорядочить строки по цветам или значкам. Сортировка данных помогает быстро визуализировать данные и лучше понимать их, упорядочивать и находить необходимую информацию и в итоге принимать более правильные решения.
Сортировать данные можно по тексту (от А к Я или от Я к А), числам (от наименьших к наибольшим или от наибольших к наименьшим), а также датам и времени (от старых к новым или от новых к старым) в одном или нескольких столбцах. Можно также выполнять сортировку по настраиваемым спискам, которые создаете вы сами (например, списку, состоящему из элементов "Большой", "Средний" и "Маленький"), или по формату, включая цвет ячеек и цвет шрифта, а также по значкам.
Примечания:
Сортировка текстовых значений
Примечания: Возможные проблемы
Сортировка чисел
Примечания:
Сортировка значений даты и времени
Примечания: Возможные проблемы
Сортировка по нескольким столбцам или строкам
Возможно, вы захотите выполнить сортировку по двум или нескольким столбцам или строкам, чтобы сгруппировать данные с одинаковыми значениями в одном столбце или строке, а затем отсортировать эти группы с одинаковыми значениями по другому столбцу или строке. Например, если есть столбцы "Отдел" и "Сотрудник", можно сначала выполнить сортировку по столбцу "Отдел" (для группировки всех сотрудников по отделам), а затем - по имени (для расположения имен сотрудников каждого отдела в алфавитном порядке). Можно одновременно выполнять сортировку по 64 столбцам.
Примечание: Для получения наилучших результатов в сортируемый диапазон нужно включить заголовки столбцов.

Сортировка по цвету ячейки, цвету шрифта или значку
Если диапазон ячеек или столбец таблицы был отформатирован вручную или с помощью условного форматирования с использованием цвета ячеек или цвета шрифта, можно также выполнить сортировку по цветам. Кроме того, можно выполнить сортировку по набору значков, созданных с помощью условного форматирования.

Сортировка по настраиваемым спискам
Для сортировки в порядке, заданном пользователем, можно применять настраиваемые списки. Например, столбец может содержать значения, по которым вы хотите выполнить сортировку, такие как "Высокий", "Средний" и "Низкий". Как настроить сортировку, чтобы сначала отображались значения "Высокий", затем - "Средний", а в конце - "Низкий"? Если отсортировать их в алфавитном порядке (от А до Я), то значения "Высокий" будут отображаться вверху, но за ними окажутся значения "Низкий", а не "Средний". А при сортировке от Я до А значения "Средний" окажутся в самом верху. В действительности значения "Средний" всегда, независимо от порядка сортировки должны отображаться в середине. Вы можете решить эту проблему, создав настраиваемый список.

Сортировка с учетом регистра
Сортировка слева направо
Как правило, сортировка выполняется сверху вниз, однако значения можно отсортировать слева направо.
Примечание: Таблицы не поддерживают возможность сортировки слева направо. Сначала преобразуйте таблицу в диапазон: выделите в ней любую ячейку и выберите пункты Работа с таблицами > Преобразовать в диапазон .
Примечание: При сортировке строк, являющихся частью структуры листа, в Excel сортируются группы наивысшего уровня (уровень 1) таким образом, что порядок расположения строк или столбцов детализации не изменится, даже если они скрыты.
Сортировка по части значения в столбце
Чтобы выполнить сортировку по части значения в столбце, например части кода (789-WDG -34), фамилии (Регина Покровская) или имени (Покровская Регина), сначала необходимо разбить столбец на две или несколько частей таким образом, чтобы значение, по которому нужно выполнить сортировку, оказалось в собственном столбце. Чтобы разбить значения в ячейке на части, можно воспользоваться текстовыми функциями или мастером текстов. Дополнительные сведения и примеры см. в статьях Разбивка текста по разным ячейкам и Разбивка текста по разным столбцам с помощью функций .
Сортировка меньшего диапазона в пределах большего
Предупреждение: Вы можете отсортировать значения в диапазоне, который является частью другого диапазона, однако делать это не рекомендуется, так как в результате будет разорвана связь между отсортированным диапазоном и исходными данными. Если отсортировать данные, как показано ниже, выбранные сотрудники окажутся связаны с другими отделами.

К счастью, Excel выдает предупреждение, если обнаруживает подобную попытку:

Если вы не собирались сортировать данные таким образом, выберите вариант автоматически расширить выделенный диапазон , в противном случае - сортировать в пределах указанного выделения .
Если результат не соответствует желаемому, нажмите кнопку Отменить .
Примечание: Отсортировать подобным образом значения в таблице нельзя.
Дополнительные сведения об основных проблемах с сортировкой
Если результаты сортировки данных не соответствуют ожиданиям, сделайте следующее.
Проверьте, не изменились ли значения, возвращаемые формулами Если сортируемые данные содержат одну или несколько формул, значения, возвращаемые ими, при пересчете листа могут измениться. В этом случае примените сортировку повторно, чтобы получить актуальные результаты.
Перед сортировкой отобразите скрытые строки и столбцы При сортировке по столбцам скрытые строки не перемещаются, а при сортировке по строкам не перемещаются скрытые столбцы. Перед сортировкой данных целесообразно отобразить скрытые строки и столбцы.
Проверьте текущий параметр языкового стандарта Порядок сортировки зависит от выбранного языка. Убедитесь в том, что на панели управления в разделе Региональные параметры или Язык и региональные стандарты задан правильный языковой стандарт. Сведения о том, как изменить параметр языкового стандарта, см. в справке Microsoft Windows.
Вводите заголовки столбцов только в одну строку Если необходимо использовать заголовки из нескольких строк, установите перенос слов в ячейке.
Включите или отключите строку заголовков Обычно рекомендуется отображать строку заголовков при сортировке по столбцам, так как она облегчает восприятие данных. По умолчанию значение в заголовке не включается в сортировку. Но в некоторых случаях может потребоваться включить или отключить заголовок, чтобы значение в заголовке включалось или не включалось в сортировку. Выполните одно из следующих действий.
Чтобы исключить из сортировки первую строку данных (заголовок столбца), на вкладке Главная в группе Редактирование нажмите кнопку Сортировка и фильтр , выберите команду Настраиваемая сортировка и установите флажок .
Чтобы включить в сортировку первую строку данных (так как она не является заголовком столбца), на вкладке Главная в группе Редактирование нажмите кнопку Сортировка и фильтр , выберите команду Настраиваемая сортировка и снимите флажок Мои данные содержат заголовки .
Команда SORT используется для сортировки в алфавитном порядке строк текстового файла или стандартного вывода.
Формат командной строки:
SORT [[диск1:][путь1]имя_файла1] [путь2]] [путь3]имя_файла3]
Параметры командной строки:
/+n - Задает число символов, n, до начала каждого сравнения. /+3 показывает, что каждое сравнение будет начинаться с третьего символа каждой строки. Строки меньше чем n символов собираются перед всеми остальными строками. По умолчанию, сравнение начинается с первого символа каждой строки.
/L язык - Перекрывает установленные в системе по умолчанию язык и раскладку заданными. Пока существует возможность только одного выбора: ""C"" - наиболее быстрый способ упорядочивания последовательности. Сортировка всегда идет без учета регистра.
/M килобайтов - Задает количество основной памяти, используемой для сортировки, в килобайтах. Размер памяти должен быть не менее 160КБ. При явном задании размера памяти именно это количество будет использовано, невзирая на то, какое количество основной памяти доступно в системе. Наилучшей производительности можно добиться, не задавая размер памяти. По умолчанию, сортировка выполняется за один проход (без временного файла), используя максимально доступный размер памяти. В остальных случаях, сортировка выполняется за два прохода (с сохранением частично отсортированных данных во временном файле), так что количество памяти, используемой для обоих проходов, - одинаково. По умолчанию, максимальный объем памяти равен 90% доступной основной памяти, если входными и выходными потоками являются файлы на диске, и 45% доступной основной памяти - иначе.
/REC символов - Определяет максимальной число символов в записи (по умолчанию 4096, максимально возможное 65535).
/R - Обратный порядок сортировки; т.е. сортировка идет от Я до А, и затем от 9 до 0.
[диск1:][путь1]имя_файла1 - Определяет имя сортируемого файла. Если оно опущено, то будет использоваться стандартный поток ввода. Явное задание сортируемого файла работает быстрее, чем перенаправление того же файла в качестве стандартного потока ввода.
/T [диск2:][путь2] - Определяет путь к папке, содержащей рабочие файлы сортировки, в том случае, когда данные не помещаются в основной памяти. По умолчанию используется системная временная папка.
/O [диск3:][путь3]имя_файла3 - Определяет имя файла, в котором сохраняются отсортированные результаты. Если оно опущено данные записываются в стандартный поток вывода. Явное задание файла вывода работает быстрее чем перенаправление стандартного потока вывода в этот же файл.
Примеры использования:
sort mytxt.txt /Output sortxt.txt - отсортировать в алфавитном порядке строки файла mytxt.txt с записью результата в файл sortxt.txt
sort sortxt.txt - то же, что и в предыдущем примере, но используется перенаправление ввода и вывода.
sort /reverse mytxt.txt /Output sortxt.txt - отсортировать в обратном порядке строки файла mytxt.txt с записью результата в файл sortxt.txt
 Приказ 343 почта. Приказ по почте россии. Последствия неявки в суд по повестке
Приказ 343 почта. Приказ по почте россии. Последствия неявки в суд по повестке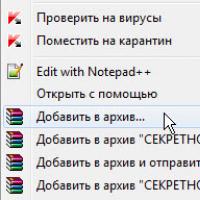 Как поставить пароль на папку в компьютере с Windows без программ и с ними
Как поставить пароль на папку в компьютере с Windows без программ и с ними Pluton – бесплатный одностраничный шаблон на Bootstrap HTML5
Pluton – бесплатный одностраничный шаблон на Bootstrap HTML5 История ZX Spectrum: Мифы и реальность Новый спектрум
История ZX Spectrum: Мифы и реальность Новый спектрум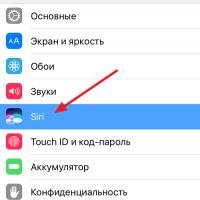 Голосовой помощник Siri от Apple Функции сири на айфон 6s
Голосовой помощник Siri от Apple Функции сири на айфон 6s Как выполнить откат до предыдущей версии iOS?
Как выполнить откат до предыдущей версии iOS?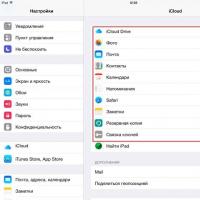 Разблокировать iPad за четыре дня
Разблокировать iPad за четыре дня